Helper resources
https://www.geeksforgeeks.org/dijkstras-shortest-path-algorithm-in-java-using-priorityqueue/
https://www.geeksforgeeks.org/dijkstras-shortest-path-algorithm-using-set-in-stl/ 最像课上教的 (heap based Dijkstra algorithm)
https://www.scaler.com/topics/data-structures/dijkstra-algorithm/
Dijkstra’s Shortest path problem
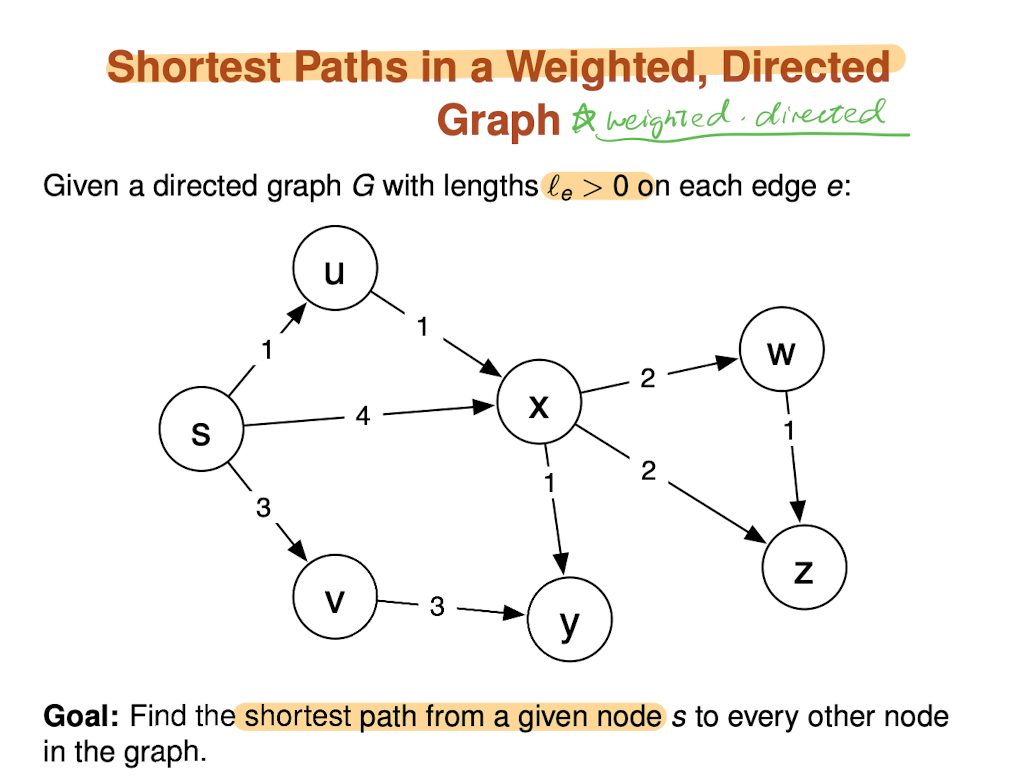
Which kind of problem to solve
Given a graph and a source vertex in the graph, find the shortest paths from the source to all vertices in the given graph.
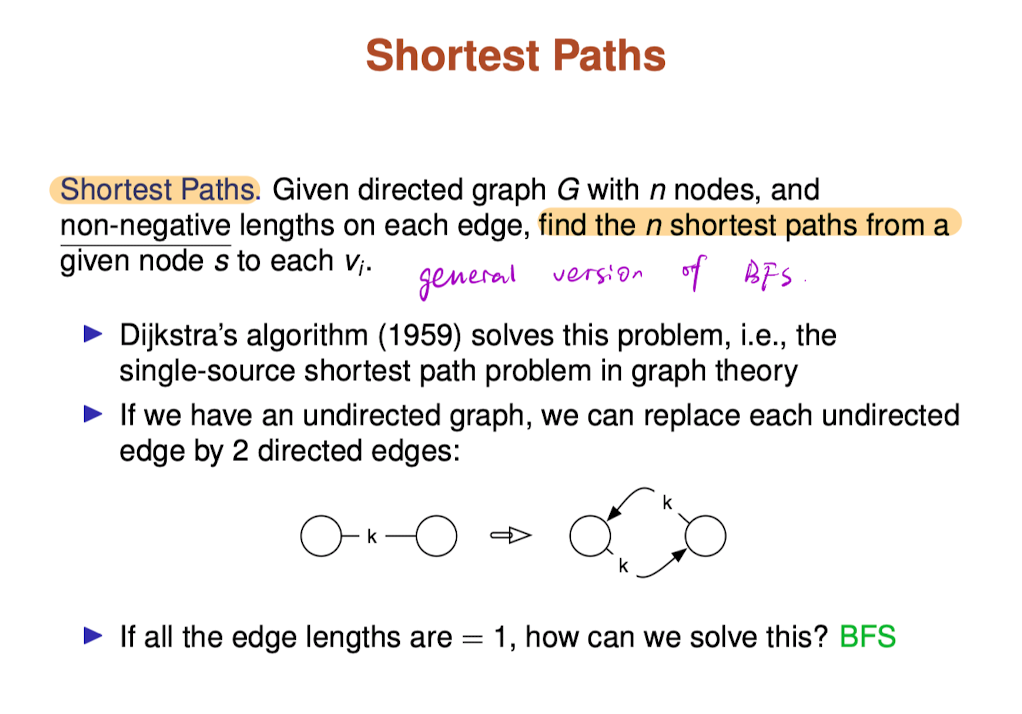
Shortest Paths and BFS
- BFS is an algorithm for finding shortest (link-distance) paths from a single source vertex to all other vertices
- BFS processes vertices in increasing order of their distance from the root vertex
Tree growing again

nextEdge for shortest path
- Let u be some node that we have already visited (it will be in S)
- Let
d(u)be the length of the s - u path found for node us nextEdge:return the frontier edge (u,v) for which d(u) + length(u,v) is minimized- The
d(u)term is the difference from Prim’s algorithm
Implementation
Heap pseudocode

Output:
Dijkstra’s algorithm would output a list of parent-child relationships (array p) and a list of source-to-node distance (array d)
Pseudocode from wiki
1 | 1) Initialize distances of all vertices as infinite. |
Drawback: while finding the shortest path as listed as follows as we need to find the least cost path by going through the whole cost array.
It can be applied to both directed and undirected graph. Here is why:
An undirected graph is basically the same as a directed graph with bidirectional connections (= two connections in opposite directions) between the connected nodes.
So you don’t really have to do anything to make it work for an undirected graph. You only need to know all of the nodes that can be reached from every given node through e.g. an adjacency list.
Java implementation
1 | package cn.itcast.algorithm.graph; |
Array based
Algorithm
1) Create a set sptSet (shortest path tree set) that keeps track of vertices included in the shortest-path tree, i.e., whose minimum distance from the source is calculated and finalized. Initially, this set is empty.
2) Assign a distance value to all vertices in the input graph. Initialize all distance values as INFINITE. Assign distance value as 0 for the source vertex so that it is picked first.
3) While sptSet doesn’t include all vertices
….a) Pick a vertex u which is not there in sptSet and has a minimum distance value.
….b) Include u to sptSet.
….c) Update distance value of all adjacent vertices of u. To update the distance values, iterate through all adjacent vertices. For every adjacent vertex v, if the sum of distance value of u (from source) and weight of edge u-v, is less than the distance value of v, then update the distance value of v.
1 | package graph; |
Original figures
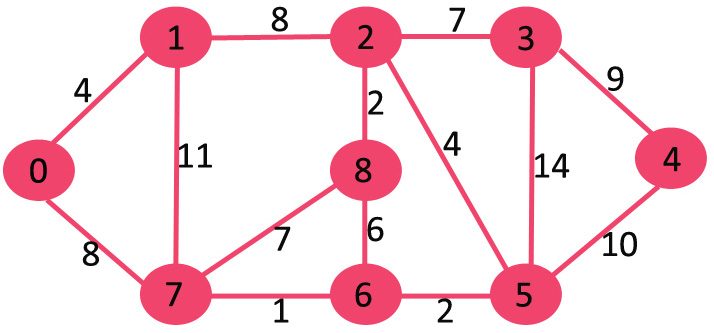
Results
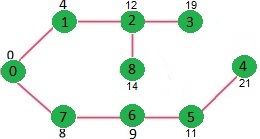
1 | Vertex Distance from Source |
Run time analysis
- Every edge is processed in the
forloop at most once - In response to that processing, we may either
- Do nothing
- Insert an item into the heap of at most V items;
O(log|V|) - Reduce the key of an item in a heap of at most
|V|items;O(log|V|)
Total Time complexity :
O(E*log(V))
Comparison with BellmanFord
Summary
Dijkstra only process the minimum edge, while Bellman-ford process every edge. This makes Bell-man ford slower, but it can handle negative edges
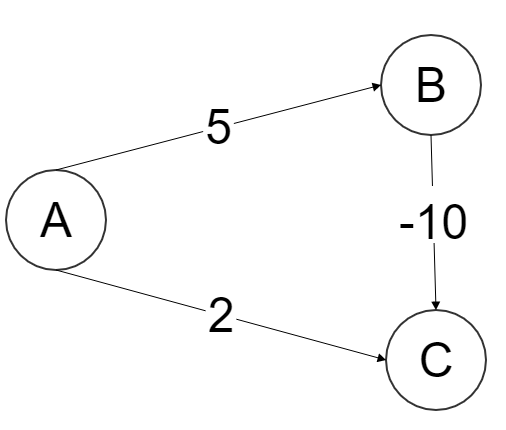
Consider the graph shown below with the source as Vertex A. First try running Dijkstra’s algorithm yourself on it.
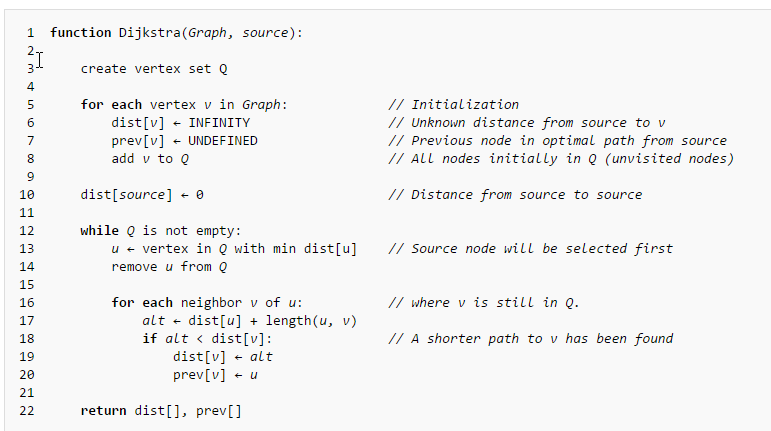
When I refer to Dijkstra’s algorithm in my explanation I will be talking about the Dijkstra’s Algorithm as implemented below,
So starting out the values (the distance from the source to the vertex) initially assigned to each vertex are,
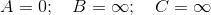
We first extract the vertex in Q = [A,B,C] which has smallest value, i.e. A, after which Q = [B, C]. Note A has a directed edge to B and C, also both of them are in Q, therefore we update both of those values,

Now we extract C as (2<5), now Q = [B]. Note that C is connected to nothing, so line16 loop doesn’t run.

Finally we extract B, after which  . Note B has a directed edge to C but C isn’t present in Q therefore we again don’t enter the for loop in
. Note B has a directed edge to C but C isn’t present in Q therefore we again don’t enter the for loop in line16,

So we end up with the distances as

Note how this is wrong as the shortest distance from A to C is 5 + -10 = -5, when you go 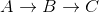 .
.
So for this graph Dijkstra’s Algorithm wrongly computes the distance from A to C.
This happens because Dijkstra’s Algorithm does not try to find a shorter path to vertices which are already extracted from Q.
What the line16 loop is doing is taking the vertex u and saying “hey looks like we can go to v from source via u, is that (alt or alternative) distance any better than the current dist[v] we got? If so lets update dist[v]“
Note that in line16 they check all neighbors v (i.e. a directed edge exists from u to v), of u which are still in Q. In line14 they remove visited notes from Q. So if x is a visited neighbour of u, the path 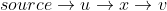
In our example above, C was a visited neighbour of B, thus the path was not considered, leaving the current shortest path
unchanged.
This is actually useful if the edge weights are all positive numbers, because then we wouldn’t waste our time considering paths that can’t be shorter.
So I say that when running this algorithm if x is extracted from Q before y, then its not possible to find a path -  which is shorter. Let me explain this with an example,
which is shorter. Let me explain this with an example,
As y has just been extracted and x had been extracted before itself, then dist[y] > dist[x] because otherwise y would have been extracted before x. (line 13 min distance first)
And as we already assumed that the edge weights are positive, i.e. length(x,y)>0. So the alternative distance (alt) via y is always sure to be greater, i.e. dist[y] + length(x,y)> dist[x]. So the value of dist[x] would not have been updated even if y was considered as a path to x, thus we conclude that it makes sense to only consider neighbors of y which are still in Q (note comment in line16)
But this thing hinges on our assumption of positive edge length, if length(u,v)<0 then depending on how negative that edge is we might replace the dist[x] after the comparison in line18.
So any dist[x] calculation we make will be incorrect if x is removed before all vertices v - such that x is a neighbour of v with negative edge connecting them - is removed.
Because each of those v vertices is the second last vertex on a potential “better” path from source to x, which is discarded by Dijkstra’s algorithm.
So in the example I gave above, the mistake was because C was removed before B was removed. While that C was a neighbour of B with a negative edge!
Just to clarify, B and C are A’s neighbours. B has a single neighbour C and C has no neighbours. length(a,b) is the edge length between the vertices a and b.
- Post title:Dijkstra algorithm
- Post author:Yuxuan Wu
- Create time:2021-10-28 10:16:23
- Post link:yuxuanwu17.github.io2021/10/28/2021-10-06-Dijkstra-algorithm/
- Copyright Notice:All articles in this blog are licensed under BY-NC-SA unless stating additionally.