Union Find algo notes
Requirements:
How could we check if adding an edge {u, v} would create a cycle
- Create a cycle if u and v are already in the same component
- Start with a component for each node
- Components merge when we add an edge
- Need to find a way to check if u and v are in same component and to merge two components into one
Data structure: Union Find
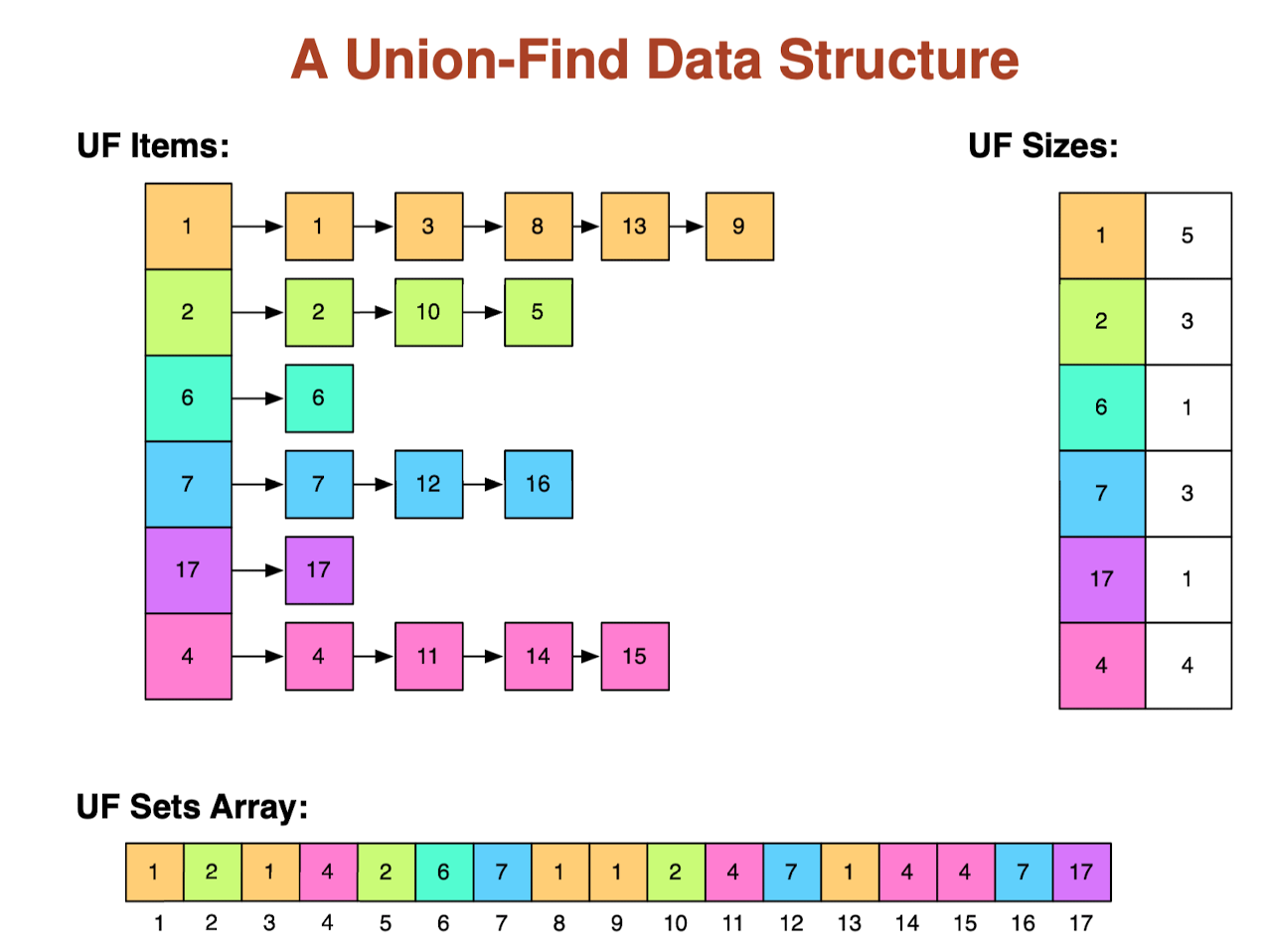
Array based UF
MakeUnionFind(S):- create the data structure containing S sets, each containing one item from S.
- Take time proportional to the size of S
Find(i):- return the “name” of the set containing item i
- Takes a constant amount of time
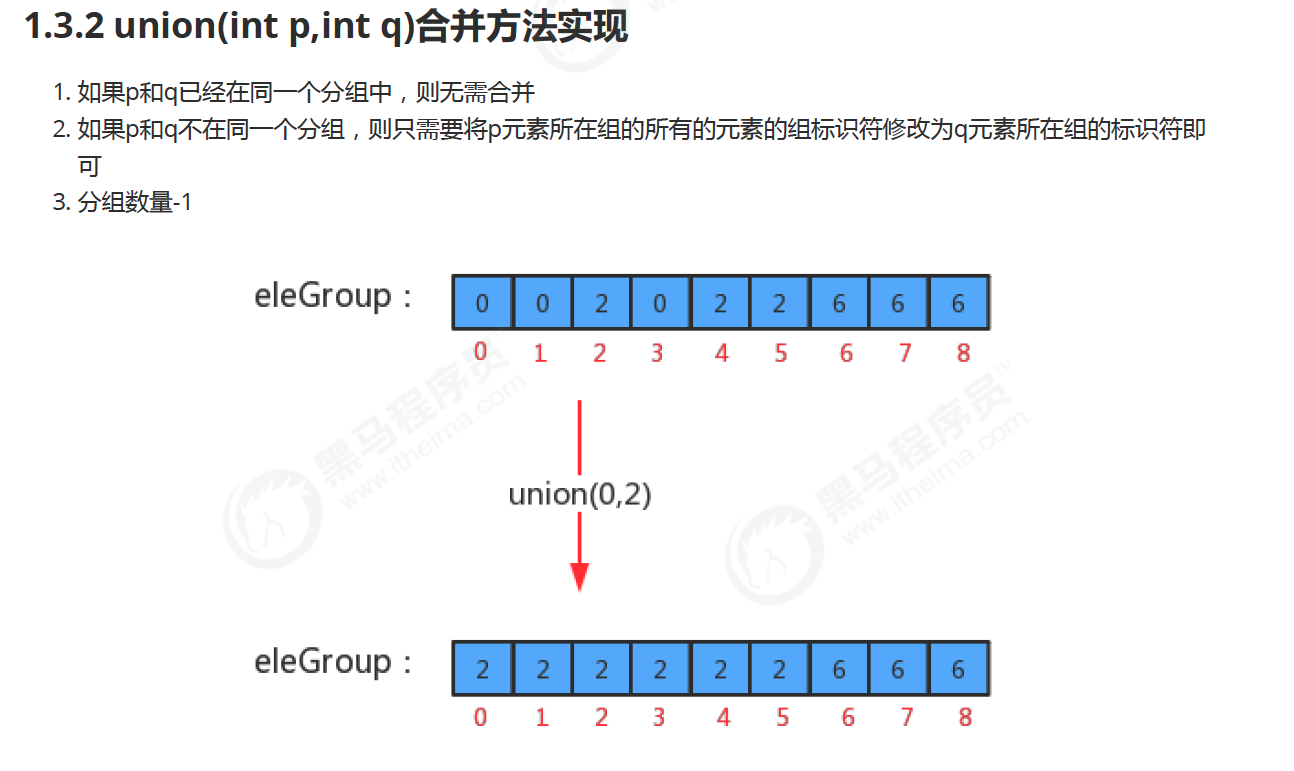
Union(a,b):- merge the sets with names a and b into a single set
- Use the “size” array to decide which set is smaller.
- Assume x is smaller, walk down elements in set x, setting
sets[i]= y. Set size[y] = size[y]+size[x]. Make y point to start of x list and end of x list point to y.
- Assume x is smaller, walk down elements in set x, setting
1 | package cn.itcast.algorithm.uf; |
Run time of array-based Union-Find
Any sequence of k union operations on a collection of n items take time at most proportional to
klogk
Proof: After k unions, at most 2k items have been involved in a union
We upper bound the number of times set[v] changes for any v:
- Every time set[v] changes, the size of the set that v is at least doubles
- Set[v] can have changed at most
In summary: at most 2k items have been modified at all, and each was updated at most
Tree-based UF
MakeUnionFind(S)- Create S trees each containing a single item and size 1 (takes time proportional to the size of S)
Find(i)- Follow the pointer from I to the root of its tree
Union(x,y)- If the size of set x is less than (<) that of y, make x point to y
- Takes constant time
- If the size of set x is less than (<) that of y, make x point to y
Runtime of tree-based Find
Find(i) takes time logn in a tree-based union-find data structure containing n items
Proof:
- the depth of an item equals the number of times the set it was in was renamed
- The size of the set containing v at least doubles every time the name of the set containing v is changed
- The largest number of times the size can double is log2n
Option used in UF
- “Find” operation too much => array based
- “Union” operation too much => tree based

- Post title:Union Find algo notes
- Post author:Yuxuan Wu
- Create time:2021-10-25 08:28:23
- Post link:yuxuanwu17.github.io2021/10/25/2021-10-25-Union-Find-algo-notes/
- Copyright Notice:All articles in this blog are licensed under BY-NC-SA unless stating additionally.