Prior Knowledge
Tree’s characteristics
- T is a tree
- T contains no cycles and n-1 edges
- T is connected and has n-1 edges
- T is connected and removing any edge disconnects it
MST problem
- Undirected graph G with vertices for each of n objects
- Non-negative weights
= cost of using edge {u,v} - T is connected and has n-1 edges
- T is connected and removing any edge disconnects it
- Any two nodes in T are connected by exactly 1 path
- T is acyclic and adding any new edge creates exactly one cycle.
For the tree MST T, we could obtain

MST property summary
Cut property: The smallest edge crossing any cut must be in all MSTs
Cycle property: the largest edge on any cycle is never in any MST
MST useful statement in HW
- Let G be a graph where every edge has a different weight. The edge with the smallest edge weight overall is in the minimum spanning tree.
The statement is holding true based on the cut property. Choose the edge e= v,w to be the minimum weight edge in the whole graph where v
set S and w V-S. Since e is the minimum weight edge overall, it is also the minimum edge that cross the cut. Therefore, this edge must be in the MST
- Let G be a graph where every edge has a different weight. There is only one, unique minimum spanning tree in this case
Suppose there is another, different MST D from original tree O. It must contain at least one differing edge d. If this edge is added to the original MST, then a cycle is created where some edge m is the maximum edge. By the cycle property, m can’t belong to any MST. Since m must belong to either D or O which are both MSTs, this leads to a contradiction.
- Let G be a graph with positive, integer weights where several edges may have the same weights. Show that for integers i, the number of edges of weight i is the same in every MST of G
Suppose not. Let T1 and T2 be two MST that do not have the same number of edges of some weights. Let e be the smallest edge that the 2 MST do not have the same number of it. Suppose T1 has more of it. Then, if we add this e to T2, there should be a cycle made since T2 is a MST. Also, because T1 is a MST, e, which is in T1 cannot be the largest edge in any cycle. Thus there must be an edge in the produced cycle which has a larger weight than e. If we replace it with e, a new spanning tree would made with smaller weights, which would contradict to that T2 is a MST. Thus the number of edges of any weight is the same in every MST of G
Greedy minimum spanning tree rules
Prim’s Algorithm
- Starting with any root node, add the frontier edge with the smallest weight
Kruskal’s Algorithm
- Add edges in increasing weight, skipping those whose addition would create a cycle.
Reverse-Delete algorithm
- Start with all edges, remove them in decreasing order of weight, skipping those whose removal would disconnect the graph
Prims

In this case distToT[u] is a indexMinPriorityQueue, which stores the distance (weight) from u to the MST tree.
- Insert (if neighbor v is not in the MST, insert into the pq)
- Update (neighbor v is in the MST, update the index in pq)
The implementation by priority queue is time complexity wise better, but is really complex as we have implemented our own priority queue. STL provides priority_queue, but the provided priority queue doesn’t support decrease key operation. And in Prim’s algorithm, we need a priority queue and below operations on priority queue :
ExtractMin: from all those vertices which have not yet been included in MST, we need to get vertex with minimum key value.DecreaseKey: After extracting vertex we need to update keys of its adjacent vertices, and if new key is smaller, then update that in data structure.
The algorithm discussed here can be modified so that decrease key is never required. The idea is, not to insert all vertices in priority queue, but only those which are not MST and have been visited through a vertex that has included in MST. We keep track of vertices included in MST in a separate boolean array inMST[].
1 | 1) Initialize keys of all vertices as infinite and |
Java implementation
API

1 | package cn.itcast.algorithm.graph; |
Time complexity
Kruskal’s algorithm
array based UF:
- Sort the edges
mlogmfor m edges (), could be rewritten as mlogn - 2m “find” operations
check wheter u and v are in the same component - At most n-1 union operations
nlogntime (UF notes)
Total running time would be mlogn + 2m + nlogn
tree based UF:
- Sorting the edges:
mlogn - At most 2m “find” operations logn time each
- At most n-1 union operations: n items
Total running time would be mlogn + 2mlogn + n
Option used in UF
- “Find” operation too much => array based
- “Union” operation too much => tree based
Clustering - Kruskal’s algorithm application
Also known as the Maximum Minimum Distance
Goal: divide the n items up into k groups so that the minimum distance between items in different group is maximized
Idea
- Maintain clusters as a set of connected components of a graph
- Iteratively combine the clusters containing the two closest items
- Stop when there are two clusters
This is exactly Kruskal’s algorithm
- The clusters are the connected components that Kruskal’s algorithm has created after a certain point
- Example of single-link, agglomerative clustering
Agglomerative: combine clusters single-link: combine as soon as a single link joins clusters.
Another way
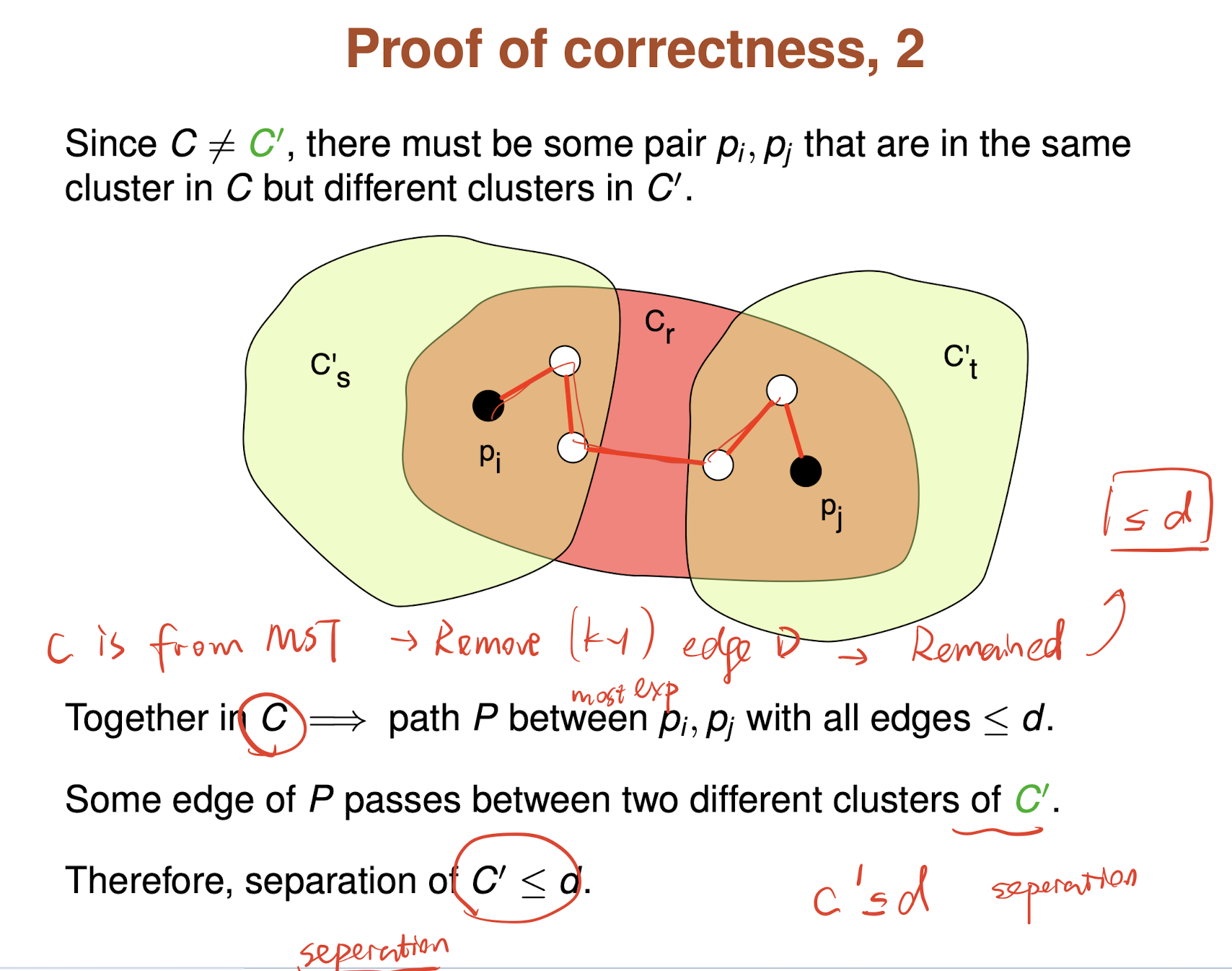
Delete the k-1 most expensive edges from the MST.
The spacing d of the clustering C that this produces is the length of the (k-1)st most expensive edge
Negative weight for MST
The concept of MST allows weights of an arbitrary sign. The two most popular algorithms for finding MST (Kruskal’s and Prim’s) work fine with negative edges.
Actually, you can just add a big positive constant to all the edges of your graph, making all the edges positive. The MST (as a subset of edges) will remain the same.
- Post title:MST algo notes
- Post author:Yuxuan Wu
- Create time:2021-10-25 08:28:23
- Post link:yuxuanwu17.github.io2021/10/25/2021-10-25-MST-algo-notes/
- Copyright Notice:All articles in this blog are licensed under BY-NC-SA unless stating additionally.