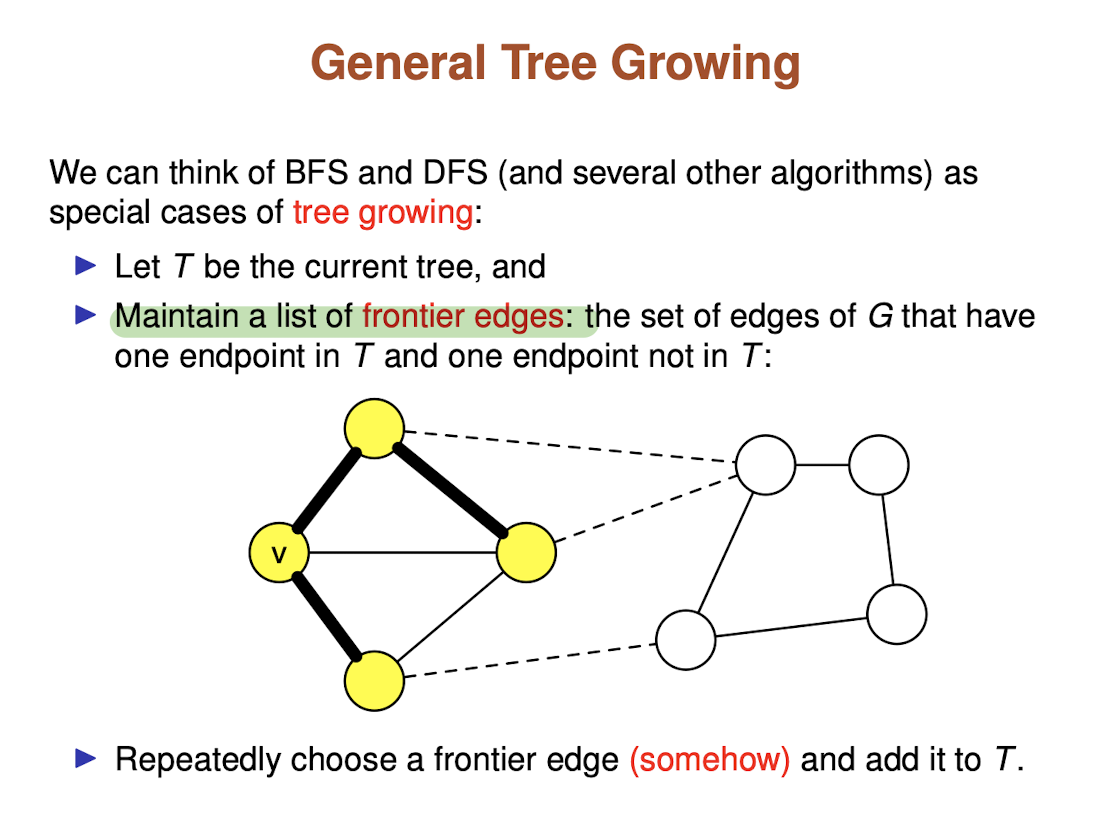
General Tree growing
- Let T be the current tree
- Maintain a list of
frontier edges: the set of edges of F that have one endpoint in T and one endpoint not in T - Repeatedly choose a frontier edge (somehow) and add it to T

Implementation of tree growing
- DFS
- BFS
- Prim’s algorithms
- Dijkstra’s shortest path
- A*
BFS & DFS as Tree Growing
nextEdge()for DFS:- Select a frontier edge whose tree endpoint was discovered
most recently(Stack) - Run time for DFS: O(E)
- Select a frontier edge whose tree endpoint was discovered
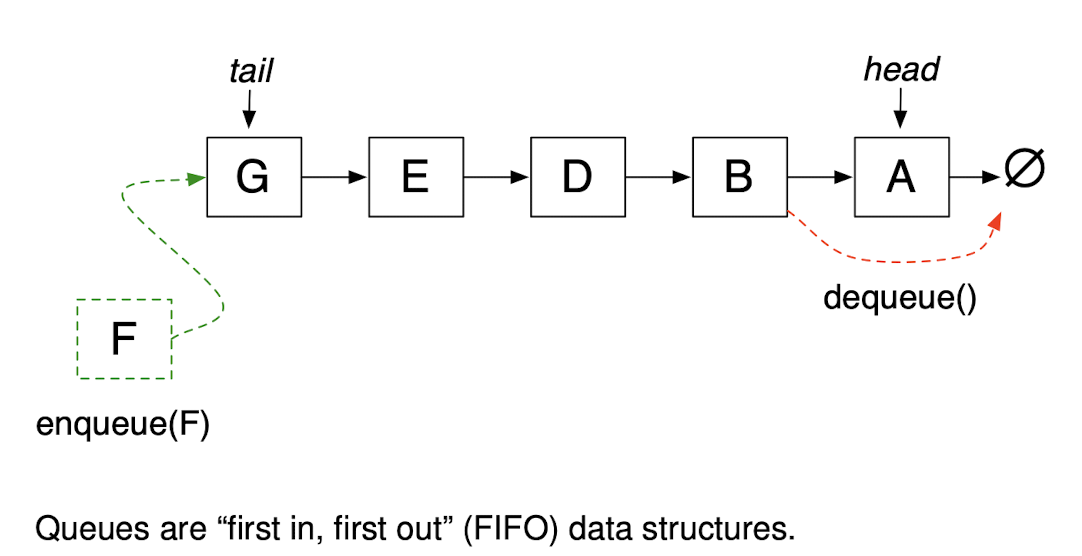
nextEdge()for BFS- Select a frontier edge whose tree endpoint was discovered
least recently(Queue) - Run time for BFS: O(E)
- Select a frontier edge whose tree endpoint was discovered
nextEdge for BFS
nextEdge: frontier edge connecting to node with earliest discovery time
A queue maintains a list of items in order of their discovery so that the item discovered farthest in the past can be accessed quickly
1 | procedure bfs(G,root) is |
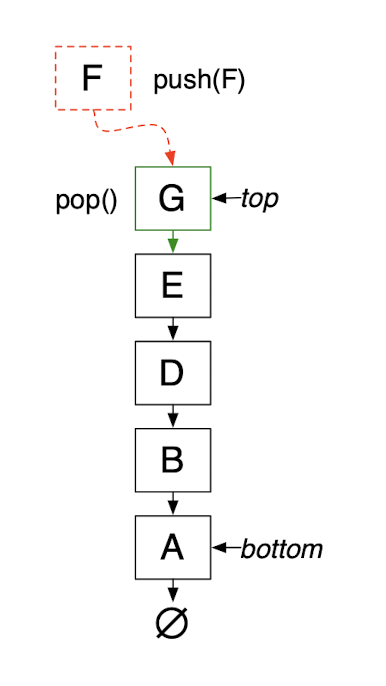
nextEdge for DFS
nextEdge: frontier edge connecting to node with latest discovery time
A stack maintains a list of items so they can be accessed in reverse order of their discovery times
A stack is a “last in, first out” (LIFO) data structure
1 | procedure DFS(G,s) |
Recursion based implementation
1 | procedure dfs (G,u) |
DFS
Basic idea
DFS keeps walking down a path until it forced to backtrack
It backtrack until find a new path to go down
The overall results would be a
DFS treeLIFO (Last IN First OUT Method)
Non-DFS-Tree edges
Theorem: Let x and y be nodes in the DFS tree
Recursive implementation of DFS
Algorithm
- Create a recursive function that takes the index of the node and a visited array
- Mark the current node/vertex as visited and print the node (this would be further code processing part)
- Traverse all the adjacency and mark all the nodes and recursively use the dfs functions
pseudo code
1 | procedure dfs (G,u) |
Java implementation
1 | package graph; |
Stack based implantation of DFS
1 | procedure DFS(G,s) |
1 | package graph; |
Comparison of recursively achieved and stack-based algorithm
These two variations of DFS visit the neighbors of each vertex in the opposite order from each other: the first neighbor of v visited by the recursive variation is the first one in the list of adjacent edges, while in the iterative variation the first visited neighbor is the last one in the list of adjacent edges.
The recursive implementation will visit the nodes from the example graph in the following order: A, B, D, F, E, C, G.
The non-recursive implementation will visit the nodes as: A, E, F, B, D, C, G.
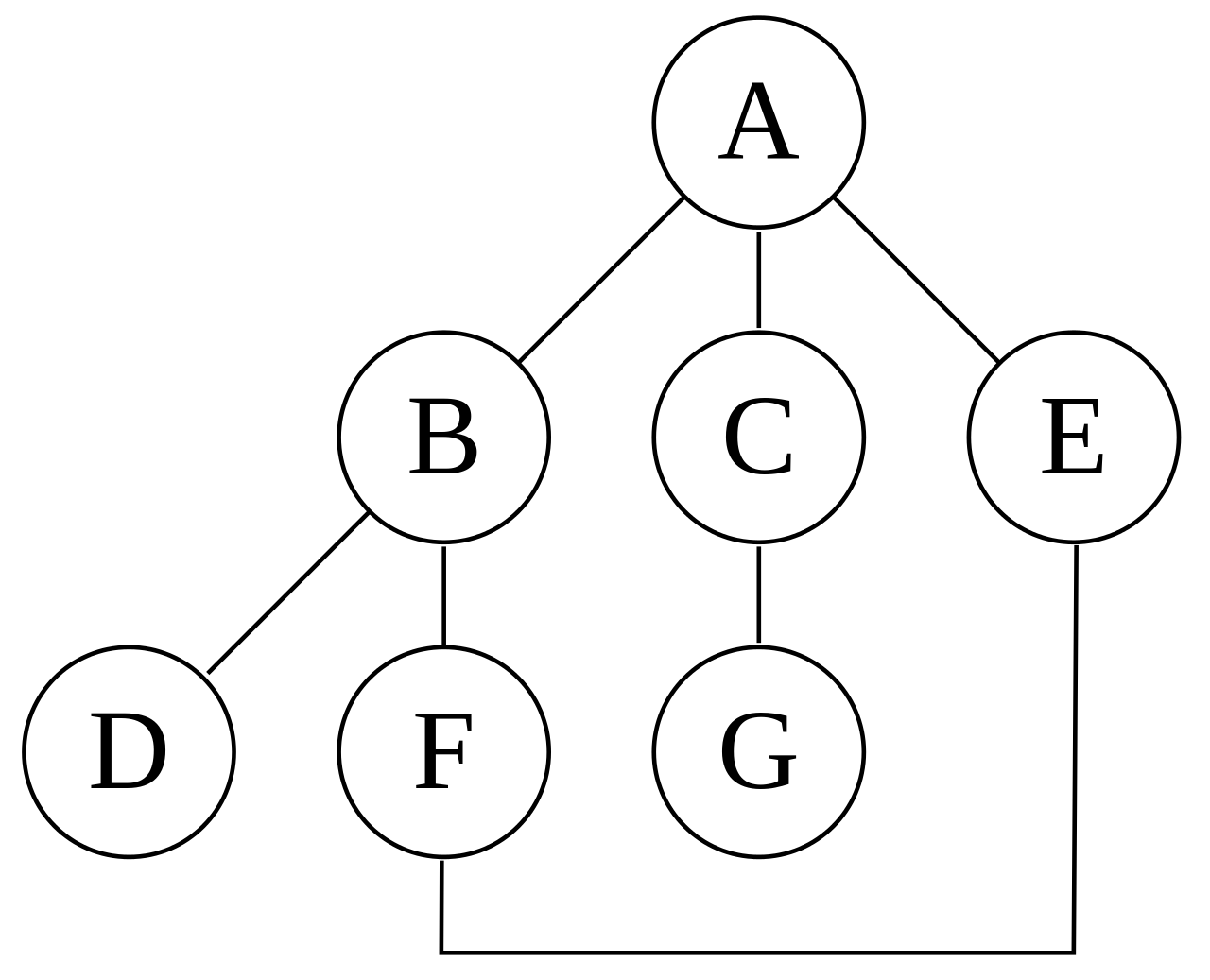
The non-recursive implementation is similar to breadth-first search but differs from it in two ways:
- it uses a stack instead of a queue, and
- it delays checking whether a vertex has been discovered until the vertex is popped from the stack rather than making this check before adding the vertex.
If G is a tree, replacing the queue of the breadth-first search algorithm with a stack will yield a depth-first search algorithm. For general graphs, replacing the stack of the iterative depth-first search implementation with a queue would also produce a breadth-first search algorithm, although a somewhat nonstandard one.[7]
Another possible implementation of iterative depth-first search uses a stack of iterators of the list of neighbors of a node, instead of a stack of nodes. This yields the same traversal as recursive DFS.[8]
Topological sorting (DFS application)
DAGs
A directed, acyclic graph (DAG) is a graph that contains no directed cycles. (After leaving any node u can never get back to u by following edges along the arrows)
DAGs are very useful in modeling project dependencies: Task i has to be done before task j and k which have to be done before m
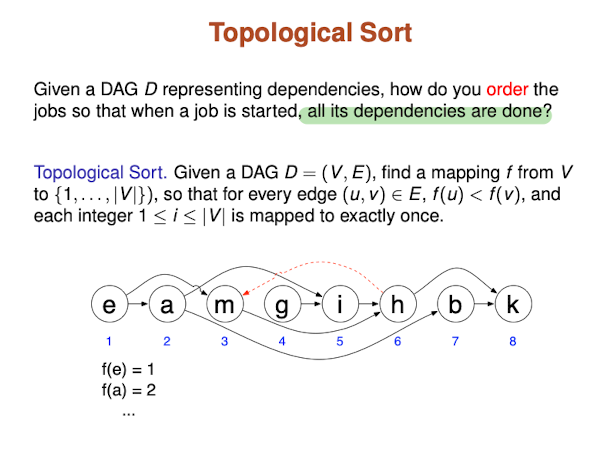
Theorem:
- Every DAG contains a vertex with no incoming edges.

- If a directed graph G is a DAF, then G has a topological ordering. Also, if a directed graph G has a topological ordering, then G is a DAG.
Being a DAG <=> having a topological ordering, because a topological ordering implies that there are no cycles in the directed graph.
Topological sorting algorithm
Topological sort:
- Let i = 1
- Find a node u with no incoming edges, and let f(u) = i
- Delete u from the graph
- Increment I
Implementation: Maintain
- Income[w] = number of incoming edges for node w
- A list S of nodes that currently have no incoming edges
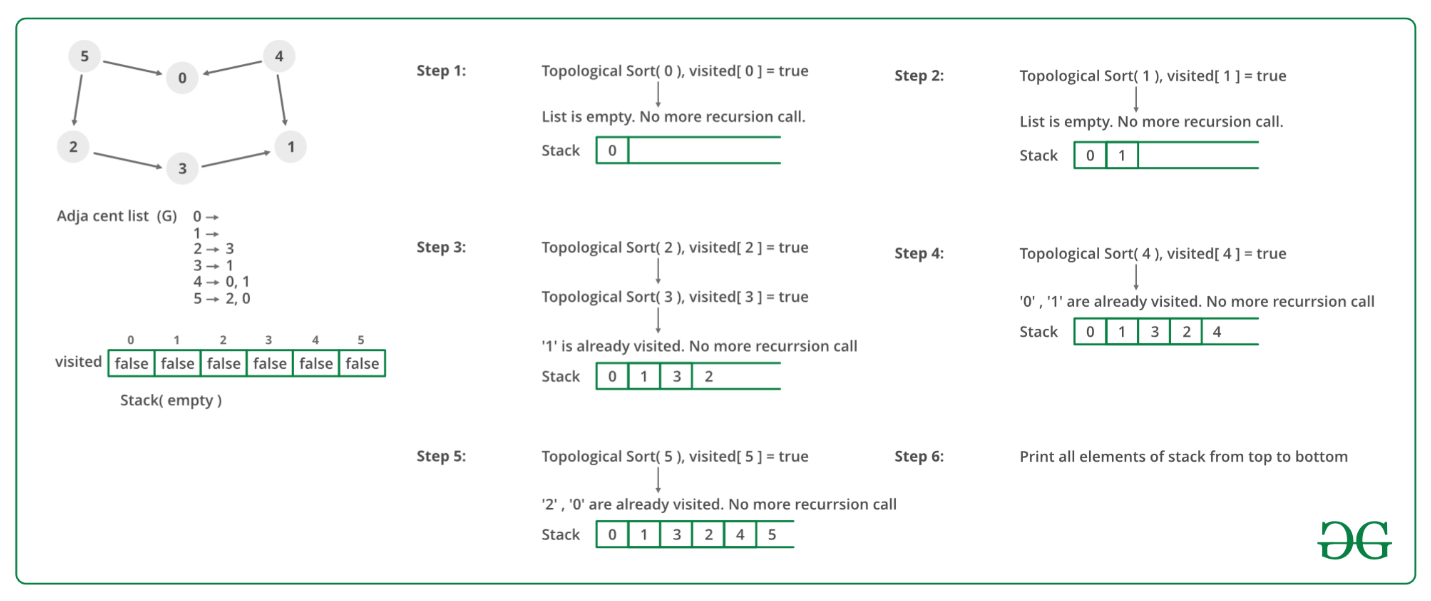
When we delete a node u, we decrement Income[w] for all neighbors w of u. If Income[w] becomes 0, we add w to S.
Topological sorting
1 | package cn.itcast.algorithm.graph; |
DepthFirstOrder
1 | package cn.itcast.algorithm.graph; |
DirectedCycle
1 | package cn.itcast.algorithm.graph; |
Run time analysis

Applications
Design an algorithm to determine whether a DAG has a unique topological ordering
We would firstly run a topological sort on G, since this is a DAG. Denote this order as L, we then check whether there is an edge going from first node in L to the second node in L. Similarly check the edge from second to third. Repeatedly check all the vertices. If all of the vertices follow the previous rules, then return true, it has a unique topological ordering, otherwise, return false.
BFS
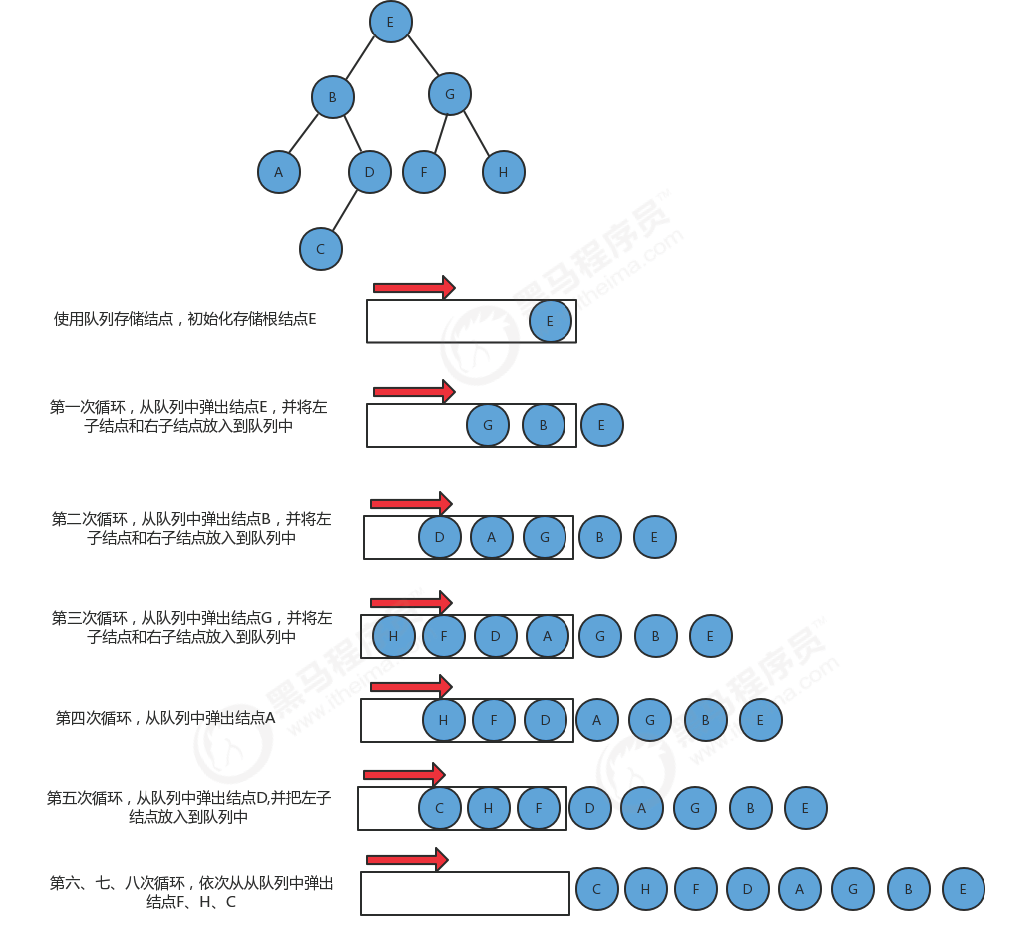
Pseudocode
1 | procedure bfs(G,root) is |
Java implementation
1 | package graph; |
Finding all connected components
Bipartiteness
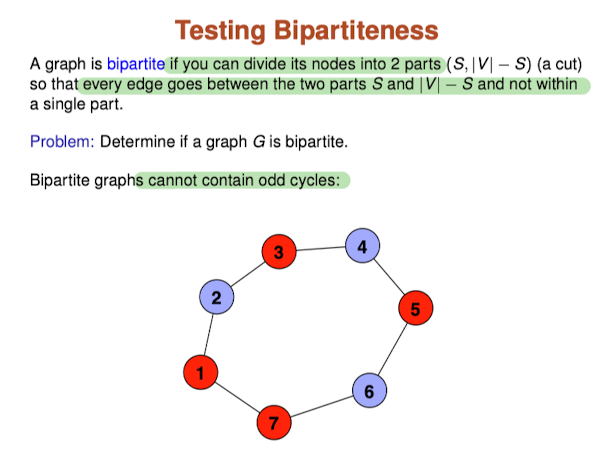
Solution:
- Do a BFS starting from some node s
- Color even levels “blue” and odd levels “red”
- Check each edge to see if any edge has both endpoints the same level
Notice:
Nodes in adjacent levels must get different colors because by construction there are edges between adjacent levels
Proof of Correctness for Bipartite Testing

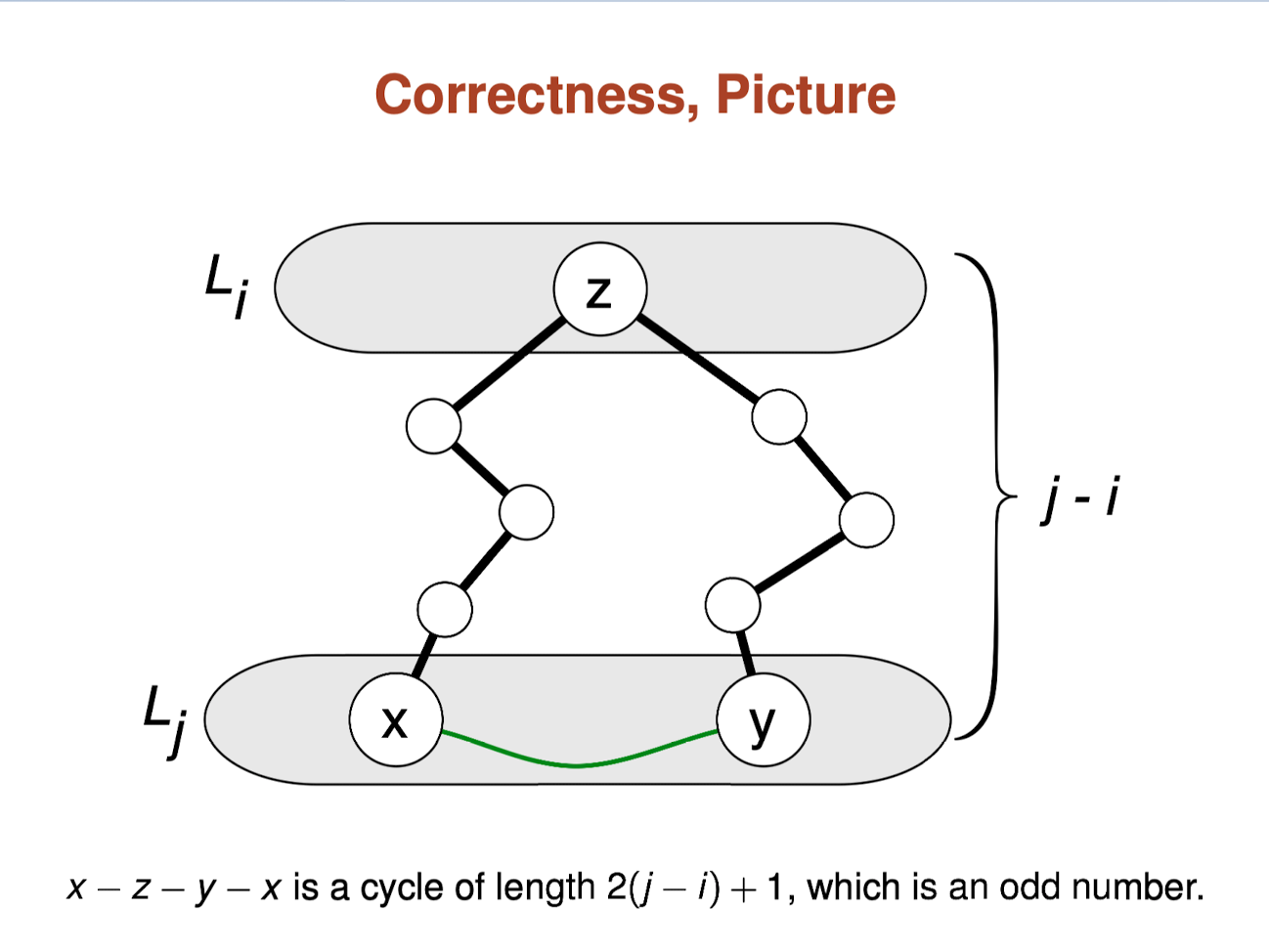
Bipartite Graph Checker
We can use the O(V+E) DFS or BFS (they work similarly) to check if a given graph is a Bipartite Graph by giving alternating color (orange versus blue in this visualization) between neighboring vertices and report ‘non bipartite’ if we ends up assigning same color to two adjacent vertices or ‘bipartite’ if it is possible to do such ‘2-coloring’ process. Try DFS_Checker or BFS_Checker on the example Bipartite Graph.
Bipartite Graphs have useful applications in (Bipartite) Graph Matching problem.
Note that Bipartite Graphs are usually only defined for undirected graphs so this visualization will convert directed input graphs into its undirected version automatically before continuing. This action is irreversible and you may have to redraw the directed input graph again for other purposes.
Applications
Detecting cycle
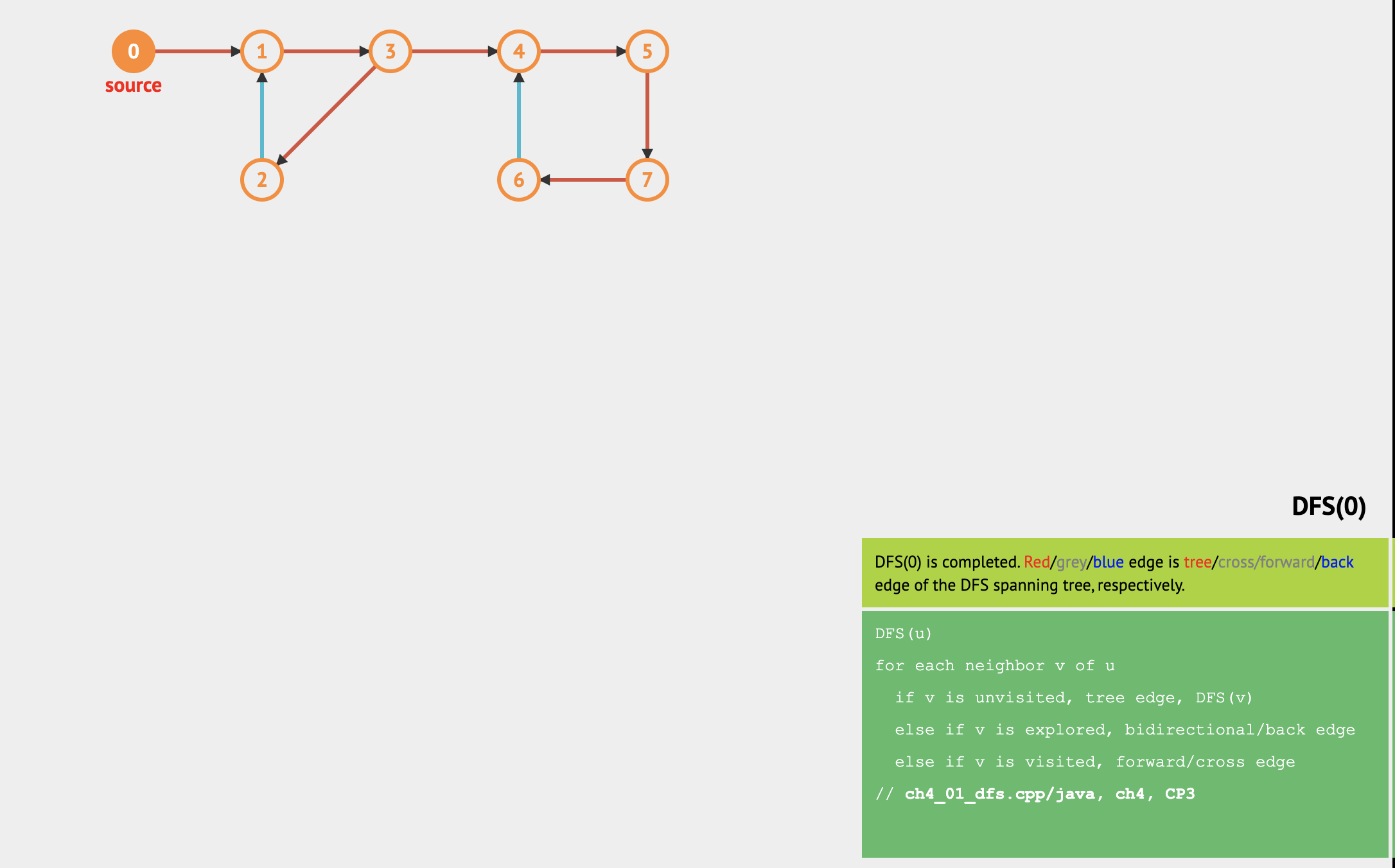
We can actually augment the basic DFS further to give more insights about the underlying graph.
In this visualization, we use blue color to highlight back edge(s) of the DFS spanning tree. The presence of at least one back edge shows that the traversed graph (component) is cyclic while its absence shows that at least the component connected to the source vertex of the traversed graph is acyclic.
Back edge can be detected by modifying array status[u] to record three different states:
- unvisited: same as earlier, DFS has not reach vertex u before,
- explored: DFS has visited vertex u, but at least one neighbor of vertex u has not been visited yet (DFS will go depth-first to that neighbor first),
- visited: now stronger definition: all neighbors of vertex u have also been visited and DFS is about to backtrack from vertex u to vertex p[u].
If DFS is now at vertex x and explore edge x → y and encounter status[y] = explored, we can declare x → y is a back edge (a cycle is found as we were previously at vertex y (hence status[y] = explored), go deep to neighbor of y and so on, but we are now at vertex x that is reachable from y but vertex x leads back to vertex y).
The edges in the graph that are not tree edge(s) nor back edge(s) are colored grey. They are called forward or cross edge(s) and currently have limited use (not elaborated).
Now try DFS(0) on the example graph above with this new understanding, especially about the 3 possible status of a vertex (unvisited/normal black circle, explored/blue circle, visited/orange circle) and back edge. Edge 2 → 1 will be discovered as a back edge as it is part of cycle 1 → 3 → 2 → 1 (similarly with Edge 6 → 4 as part of cycle 4 → 5 → 7 → 6 → 4).
We can use following simple recursive function to print out the path stored in array p. Possible follow-up discussion: Can you write this in iterative form? (trivial)
1 | method backtrack(u) |
To print out the path from a source vertex s to a target vertex t in a graph, you can call O(V+E) DFS(s) (or BFS(s)) and then O(V) backtrack(t). Example: s = 0 and t = 4, you can call DFS(0) and then backtrack(4). When we call backtrack(4) after executing DFS(0) on the sample graph, we go back from 4 → p[4] = 3 → p[3] = 2 → p[2] = 1 → p[1] = 0 → p[0] = -1 (so 0 is the source) and print the path in reversed order (due to recursion) i.e.: 0 → 1 → 2 → 3 → 4.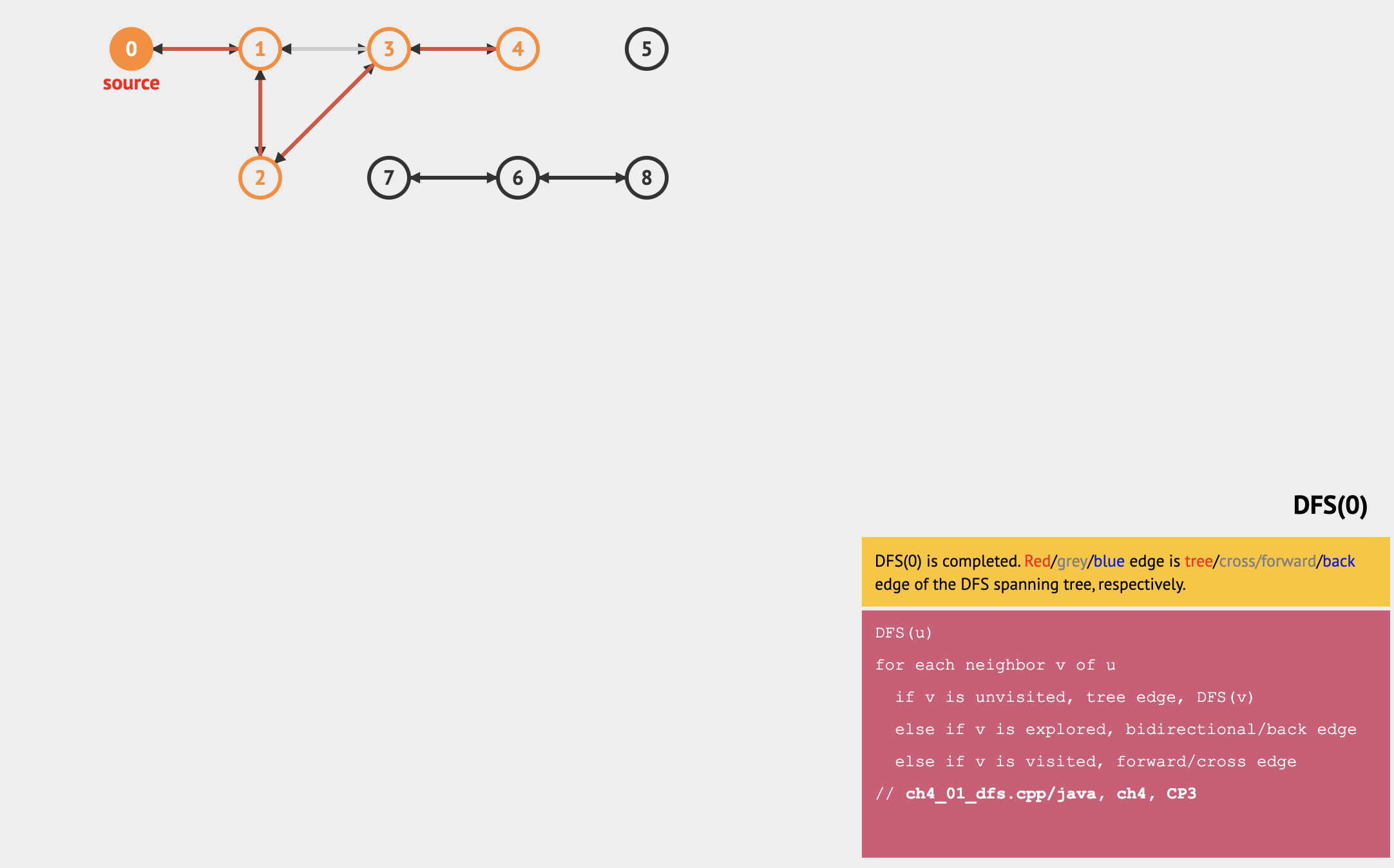
Q4 in midterm practice
Design an algorithm to take an undirected, connected graph G(V,E) and give each of its edge a direction such the following two conditions are satisfied:
- The resulting directed graph contains a tree all of whose edges point away from the root
- Any edge that does not belong to the above tree forms a directed cycle with edges of the tree (A directed cycle is a cycle in which all the edges are going the same way)
Answer
We shall run DFS to produce a tree and then flip the edges not in the tree appropriately
- Run DFS. As we traverse the edges during DFS we create the directed edge from parent to child, ensuring that all edges face away from the root. At the same time, we timestamp each node such that we know the order in which we visited them (which will be necessary to easily decide the direction of non-tree edges) This satisfies the first condition.
- We then deal with the remaining edges. Every edge will connect two nodes, and every node is timestamped. We direct non-tree edges from the more recent node to the older node. This ensures that it points back to a node that will form a cycle (and this relies on the traversal ordering provided by DFS)
- Post title:DFS and BFS algo notes
- Post author:Yuxuan Wu
- Create time:2021-10-03 09:47:23
- Post link:yuxuanwu17.github.io2021/10/03/2021-10-03-DFS-and-BFS-algo-notes/
- Copyright Notice:All articles in this blog are licensed under BY-NC-SA unless stating additionally.