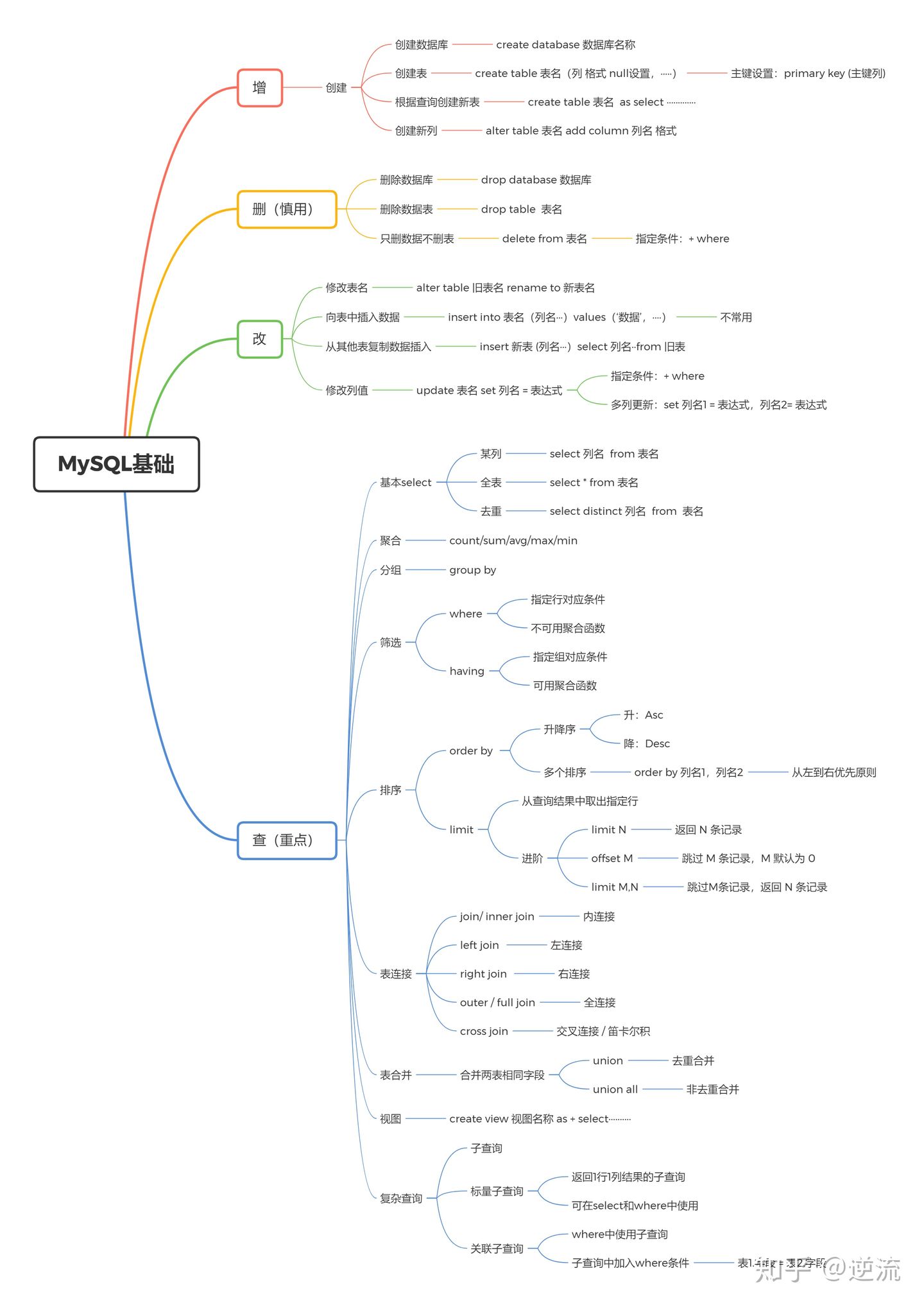
MySQL 知识图谱
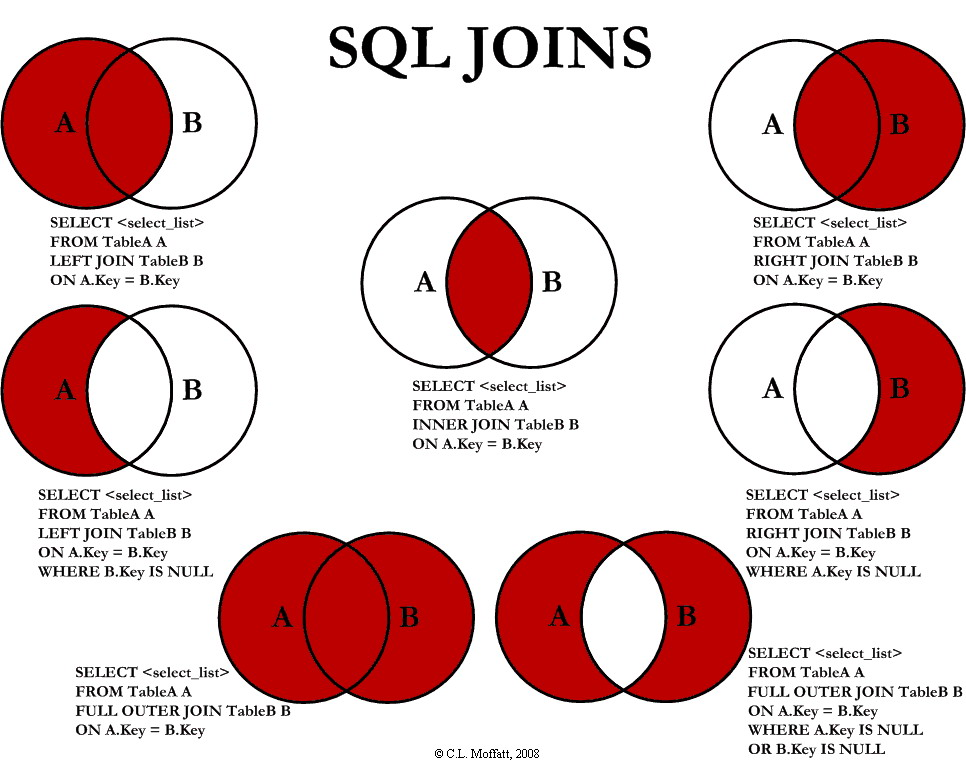
Join 连接大全
175. Combine Two Tables
1 | Table: Person |
PersonId is the primary key column for this table.
1 | Table: Address |
AddressId is the primary key column for this table.
Write a SQL query for a report that provides the following information for each person in the Person table, regardless if there is an address for each of those people:
1 | FirstName, LastName, City, State |
1 | select p.FirstName,p.LastName,a.City,a.State |
1)注意审题: 题目说:无论 person 是否有地址信息,都需要基于上述两表提供 person 的以下信息: FirstName, LastName, City, State 也就是说,地址信息(City, State)的查询结果是Null是OK的。但是,姓名(FirstName, LastName)必须有。
2) 为啥不用Where? 因为where的实质就是根据你给的条件(personID相等),选取两表的公共部分。但是,因为PERSON表不是所有人都有地址信息的,但是ADDRESS表只显示有地址信息的人,这样选取出来的就是有地址信息的人,漏掉了没有地址信息的人。所以大家注意,where的本质就是过滤。
3) 如何连接?应该用PERSON表左连接(left join)ADDRESS表,保留person表的所有信息
176. Second Highest Salary
Write a SQL query to get the second highest salary from the Employee table.
1 | +----+--------+ |
For example, given the above Employee table, the query should return 200 as the second highest salary. If there is no second highest salary, then the query should return null.
1 | +---------------------+ |
- 要想获取第二高,需要排序,使用 order by(默认是升序 asc,即从小到大),若想降序则使用关键字 desc
- 去重,如果有多个相同的数据,使用关键字 distinct 去重
- 判断临界输出,如果不存在第二高的薪水,查询应返回 null,使用 ifNull(查询,null)方法
- 起别名,使用关键字 as …
- 因为去了重,又按顺序排序,使用 limit()方法,查询第二大的数据,即第二高的薪水,即 limit(1,1) (因为默认从0开始,所以第一个1是查询第二大的数,第二个1是表示往后显示多少条数据,这里只需要一条)
1 | select ifNull(( |
177. Nth Highest Salary
Write a SQL query to get the nth highest salary from the Employee table.
1 | +----+--------+ |
For example, given the above Employee table, the nth highest salary where n = 2 is 200. If there is no nth highest salary, then the query should return null.
1 | +------------------------+ |
1 | CREATE FUNCTION getNthHighestSalary(N INT) RETURNS INT |
- 题目是 176.第二高的薪水 的变形,将查询第二名变成查询 第N名
- 别名中不能带参数,一开始看到测试用例表,使用的别名是getNthHighestSalary(2),就用了getNthHighestSalary(N)做别名,一开始报错还不知道是哪,后面删去变量即可
- limit()方法中不能参与运算,因为索引从0开始,所以要 - 1,最好在外面就设定好 set N = N - 1
需要注意的点就是:
limit是不可以做运算的
178. Rank Scores
Write a SQL query to rank scores. If there is a tie between two scores, both should have the same ranking. Note that after a tie, the next ranking number should be the next consecutive integer value. In other words, there should be no “holes” between ranks.
1 | +----+-------+ |
For example, given the above Scores table, your query should generate the following report (order by highest score):
1 | +-------+---------+ |
Important Note: For MySQL solutions, to escape reserved words used as column names, you can use an apostrophe before and after the keyword. For example Rank.
思路:
- 从两张相同的表scores分别命名为s1,s2。
- s1中的score与s2中的score比较大小。意思是在输出s1.score的前提下,有多少个s2.score大于等于它。比如当s1.salary=3.65的时候,s2.salary中[4.00,4.00,3.85,3.65,3.65]有5个成绩大于等于他,但是利用count(distinct s2.score)去重可得s1.salary3.65的rank为3
- group by s1.id 不然的话只会有一条数据
- 最后根据s1.score排序desc
1 | select s1.score,count(distinct s2.score) as rank |
最后的结果包含两个部分,第一部分是降序排列的分数,第二部分是每个分数对应的排名。
第一部分不难写:
1 | select a.Score as Score |
比较难的是第二部分。假设现在给你一个分数X,如何算出它的排名Rank呢?
我们可以先提取出大于等于X的所有分数集合H,将H去重后的元素个数就是X的排名。比如你考了99分,但最高的就只有99分,那么去重之后集合H里就只有99一个元素,个数为1,因此你的Rank为1。
先提取集合H:
1 | select b.Score from Scores b where b.Score >= X; |
我们要的是集合H去重之后的元素个数,因此升级为:
1 | select count(distinct b.Score) from Scores b where b.Score >= X as Rank; |
而从结果的角度来看,第二部分的Rank是对应第一部分的分数来的,所以这里的X就是上面的a.Score,把两部分结合在一起为:
1 | select a.Score as Score, |
180. Consecutive Numbers
Table: Logs
1 | +-------------+---------+ |
Write an SQL query to find all numbers that appear at least three times consecutively.
Return the result table in any order.
The query result format is in the following example:
1 | Logs table: |
方法一:
- 根据
num列相等对logs表进行自连接 - 根据
l1.id进行聚合分组 - 若分组中满足
l1.id与l2.id的差在0到2之间的l2.id大于2个,则说明该num连续出现3次
1 | select distinct l1.num consecutivenums |
方法二:
- 根据
num列相等,以及id之差的范围在0到2之间,对logs表进行自连接 - 根据
l1.id进行聚合分组 - 统计分组中
l2.id的数目,若大于2即满足题意
1 | select distinct l1.num consecutivenums |
方法三:
1 | select distinct a.num as ConsecutiveNums |
181. Employees Earning More Than Their Managers
The Employee table holds all employees including their managers. Every employee has an Id, and there is also a column for the manager Id.
1 | +----+-------+--------+-----------+ |
Given the Employee table, write a SQL query that finds out employees who earn more than their managers. For the above table, Joe is the only employee who earns more than his manager.
1 | +----------+ |
答案
1 | select e1.name as `Employee` from Employee e1, Employee e2 |
182. Duplicate Emails
Write a SQL query to find all duplicate emails in a table named Person.
1 | +----+---------+ |
For example, your query should return the following for the above table:
1 | +---------+ |
1 | -- 解法1 |
183. Customers Who Never Order
Suppose that a website contains two tables, the Customers table and the Orders table. Write a SQL query to find all customers who never order anything.
Table: Customers.
1 | +----+-------+ |
Table: Orders.
1 | +----+------------+ |
Using the above tables as example, return the following:
1 | +-----------+ |
1 | select c.name as `Customers` |
1 | SELECT Name 'Customers' |
- Post title:MySQL(LC算法)
- Post author:Yuxuan Wu
- Create time:2021-08-01 16:04:23
- Post link:yuxuanwu17.github.io2021/08/01/2021-08-01-MySQL(LC算法)/
- Copyright Notice:All articles in this blog are licensed under BY-NC-SA unless stating additionally.