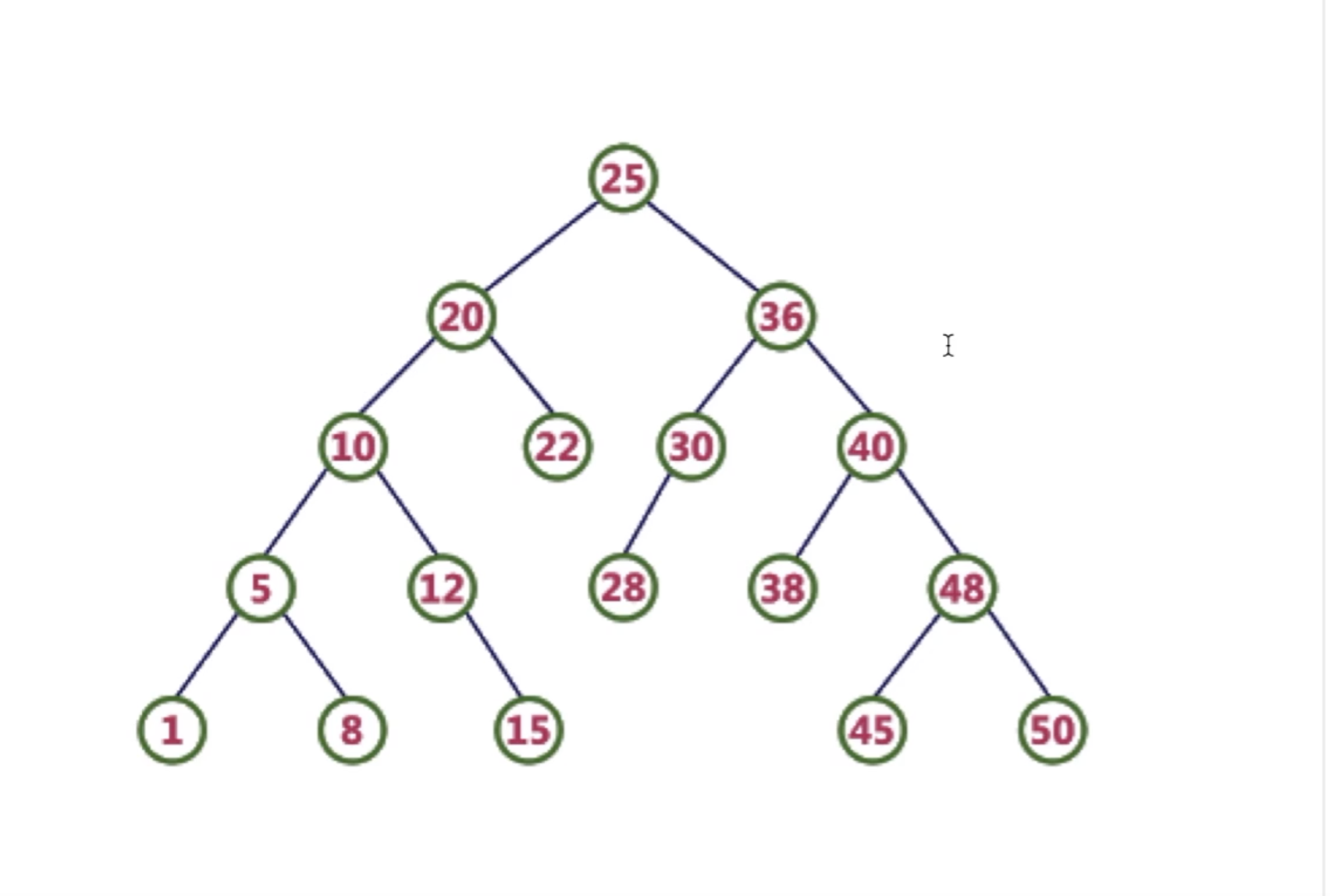
// 先判断是否存在,不存在则让输入为root if (root == null) { root = new TreeNode(key); return; }
// current 代表你要插入的值 // parent 插入的父亲
TreeNode current = root; TreeNode parent = null; while (true) { parent = current; if (key < parent.value) { current = parent.left; if (current == null) { parent.left = new TreeNode(key); return; } } elseif (key > parent.value) { current = parent.right; if (current == null) { parent.right = new TreeNode(key); return; } } else { return; // BST does not allow nodes with the same value } } }
/** * 删除需要考虑三种情况 * <p> * Case 1: if node to be deleted has no children (删除节点没有子节点) * Case 2: if node to be deleted has only one child (删除节点有一个子节点,可以是左,也可以是右) * Case 3: current.left != null && current.right != null (删除节点有两个节点,左右节点都存在) * * https://www.bilibili.com/video/BV1qQ4y1M7Z4 * * @param key * @return * @insideparam parent: 用来记录上一个父亲节点 * @insideparam current:用来记录当前的节点 */ publicbooleandelete(int key){ TreeNode parent = root; TreeNode current = root; boolean isLeftChild = false; while (current != null && current.value != key) { parent = current; if (current.value > key) { isLeftChild = true; current = current.left; } else { isLeftChild = false; current = current.right; } } if (current == null) { returnfalse; } // Case 1: if node to be deleted has no children if (current.left == null && current.right == null) { if (current == root) { root = null; } elseif (isLeftChild) { parent.left = null; } else { parent.right = null; } // Case 2: if node to be deleted has only one child } elseif (current.right == null) { if (current == root) { root = current.left; } elseif (isLeftChild) { parent.left = current.left; // 和下方不一致的主要是current.left 和current.right 的区别 } else { parent.right = current.left; } } elseif (current.left == null) { if (current == root) { root = current.right; } elseif (isLeftChild) { parent.left = current.right; } else { parent.right = current.right; } // Case 3: current.left != null && current.right != null // 找右子树上的最小的节点来替代--> successor } else { // 这一步是获得最小的节点 TreeNode successor = getSuccessor(current); if (current == root) { root = successor; } elseif (isLeftChild) { parent.left = successor; } else { parent.right = successor; } successor.left = current.left; } returntrue; }
private TreeNode getSuccessor(TreeNode node){ // 找右子树上的最小的节点来替代--> successor // 同时遵循保证树形结构的完整 TreeNode successor = null; // 最后需要放上去的那个节点 TreeNode successorParent = null; TreeNode current = node.right; // 找到待删除位置的sub右子树上找到最小的点 // 这里的while循环已经保证了最小左子树,但是没法保证最小左子树是否含有右节点 while (current != null) { successorParent = successor; successor = current; current = current.left; }
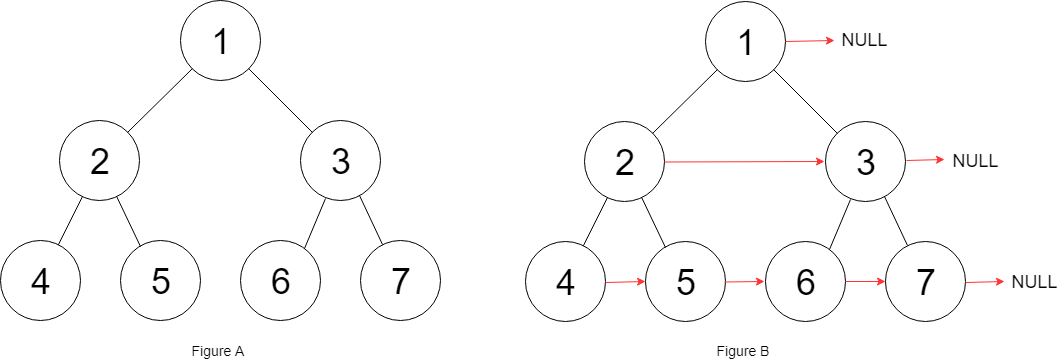
You are given a perfect binary tree where all leaves are on the same level, and every parent has two children. The binary tree has the following definition:
Populate each next pointer to point to its next right node. If there is no next right node, the next pointer should be set to NULL.
Initially, all next pointers are set to NULL.
Follow up:
You may only use constant extra space.
Recursive approach is fine, you may assume implicit stack space does not count as extra space for this problem.
Example 1:
1 2 3
Input: root = [1,2,3,4,5,6,7] Output: [1,#,2,3,#,4,5,6,7,#] Explanation: Given the above perfect binary tree (Figure A), your function should populate each next pointer to point to its next right node, just like in Figure B. The serialized output is in level order as connected by the next pointers, with '#' signifying the end of each level.
Serialization is the process of converting a data structure or object into a sequence of bits so that it can be stored in a file or memory buffer, or transmitted across a network connection link to be reconstructed later in the same or another computer environment.
Design an algorithm to serialize and deserialize a binary tree. There is no restriction on how your serialization/deserialization algorithm should work. You just need to ensure that a binary tree can be serialized to a string and this string can be deserialized to the original tree structure.
Clarification: The input/output format is the same as how LeetCode serializes a binary tree. You do not necessarily need to follow this format, so please be creative and come up with different approaches yourself.
public TreeNode deserializable(String data){ LinkedList<String> nodes = new LinkedList<>(); for (String s : data.split(SEP)) { nodes.addLast(s); } return deserializable(nodes); }
public TreeNode deserializable(LinkedList<String> nodes){ if (nodes.isEmpty()) returnnull; String first = nodes.removeFirst(); if (first.equals(NULL)) returnnull; TreeNode root = new TreeNode(Integer.parseInt(first));
Given two integer arrays preorder and inorder where preorder is the preorder traversal of a binary tree and inorder is the inorder traversal of the same tree, construct and return the binary tree.
int count(TreeNode root) { if (root == null) { return 0; } // 先算出左右子树有多少节点 int left = count(root.left); int right = count(root.right); /* 后序遍历代码位置 */ // 加上自己,就是整棵二叉树的节点数 int res = left + right + 1; return res; }

](https://assets.leetcode.com/uploads/2021/02/19/tree.jpg)