一、 Beanstalkd 是什么
Beanstalkd,一个高性能、轻量级的分布式内存队列系统,后台异步执行
二、 Beanstalkd 特性
注:优先级就意味 支持任务插队(数字越小,优先级越高,0的优先级最高)
注:延迟意味着可以定义任务什么时间才开始被消费,也就实现了定时任务(比如为了增加网站活跃性,增加定时评论,定时点赞功能)
注:Beanstalkd 支持定时将文件刷到日志文件里,即使beanstalkd宕机,重启之后仍然可以找回文件
注:Beanstalkd支持把一个任务设置为预留,这样,消费者就无法取出这个任务了,等合适的时机再把这个任务拿出来消费
注:消费者必须在指定的时间内处理完这个任务,否则就认为消费者处理失败,任务会被重新放到队列,等待消费
注:beanstalkd 的分布式,需要通过客户端自己实现。即,比如你有10台消息队列服务器,此时,你需要全部部署上beanstalkd,并且自己编写分布式的中间代码
三、 管道(tube)与任务(job)
注:生产者生产任务,并根据业务需求将任务放到不同管道中,比如和注册有关的任务放到注册管道中,和订单有关的放到订单管道中
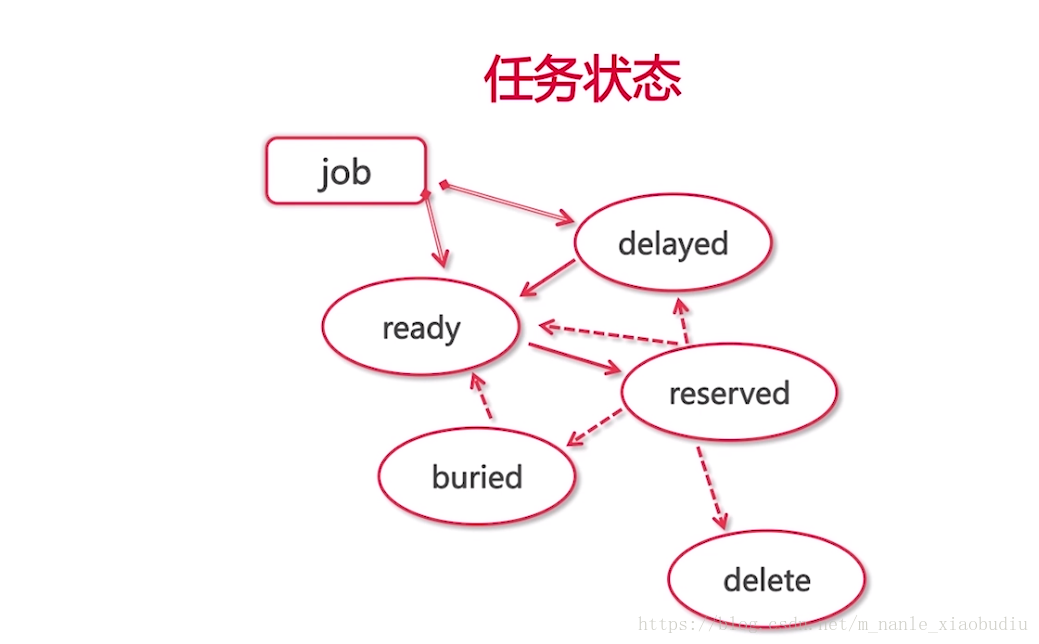
注:任务从进入管道到离开管道一共有5个状态(ready,delayed,reserved,buried,delete)
生产者-> 管道(tube)->任务(job)-> 消费者
Job: 一个需要异步处理的任务,需要放在一个tube中
tube:一个有名字的队列,用来存储同一类型的job,可以创建多个管道
producer: job 的生产者
consumer:job的消费者
简单流程:由producer产生的一个任务job, 并且将job推进到一个tube中,然后投consumer从tube中取出执行
具体流程
- 生产者将任务放到管道中,任务的状态可以是ready(表示任务已经准备好,随时可以被消费者读取),也可以是delayed(任务在被生产者放入管道时,设置了延迟,比如设置了5s延迟,意味着5s之后,这个任务才会变成ready状态,才可以被消费者读取)
- 消费者消费任务(消费者将处于ready状态的任务读出来后,被读取处理的任务状态变为reserved)
- 消费者处理完任务后,任务的状态可能是delete(删除,处理成功),可能是buried(预留,意味着先把任务放一边,等待条件成熟还要用),可能是ready,也可能是delayed,需要根据具体业务场景自己进行判断定义
四、Beanstalkd 消息队列
Beanstalked是一个轻量级的 高性能的分布式内存队列
常用的队列服务 RabbitMQ、kafka
队列的特性是:先进先出
队里的应用场景
1、异步处理(最重要): 比如说注册时对与注册成功之后可以立即返回注册成功页面,之后将客户的端口监听队列 达到异步的效果 提高整体的响应速度
2、系统解耦
3、定时任务:对于新上线的产品,可以运用beanstalkd来做马甲,增添定时的内容发表及点赞
运行模式:生产者与消费者
Beanstalked特性:
1.优先级(priority)插队、
2.延迟(delay)定时任务或指定时间之后才可以读取队列
3.持久化(persistent data)-》通过beanlog日志文件存储信息
4.预留(buried)可以将某个数据设置成预留 等到时机成熟时再拿出
5.任务超时重发(time-to-run)消费者必须在指定的时间之内处理完这个业务 否则就人物消费者处理失败了
Beanstalked的核心元素:
1.tube(管道):就好比排队的通道 beanstalked可以创建多个管道 进而可以定义不同管道的应用场景 和 特性。
2.job(任务)
Beanstalked的任务状态:
小结:任务在进入管道到离开管道一共有五个状态
put reserve delete
-----> [READY] ---------> [RESERVED] --------> *poof*
Here is a picture with more possibilities:
put with delay release with delay
----------------> [DELAYED] <------------.
| |
| (time passes) |
| |
put v reserve | delete
-----------------> [READY] ---------> [RESERVED] --------> *poof*
^ ^ | |
| \ release | |
| `-------------' |
| |
| kick |
| |
| bury |
[BURIED] <---------------'
|
| delete
`--------> *poof*
释义:
ready 是准备好了随时可以给消费者读取
delayed 是延迟的 在放入管道时就有延时的秒数
delete 是删除
buried 是预留 待条件成熟之后再次使用 再次ready1 | Job Lifecycle |
具体示意图:
五、 Beanstalkd 的安装
MAC 安装
可以直接去官方文档上查看,因为我使用的是阿里云centos,git clone不下来,建议用其他方式
1 | brew install beanstalkd |
Once Composer is installed, this one-liner will install and configure the beanstalk_console monitor (replace path/to/install to your desired install location):
1 | composer create-project ptrofimov/beanstalk_console -s dev /Users/yuxuan/beanskalkd |
We’ll also create a helper run.sh script inside the path/to/install directory. This script prepares your dev environment by restarting Beanstalkd, launching a local PHP server with the monitor, and finally opening a new tab on Chrome pointing to it (127.0.0.1:8005).
1 | !/bin/bash |
Linux
linux 安装 beanstalkd 并不难。
我们知道,linux 自定义安装(编译安装),一般经历这么几步:
- wget (或者压缩包已经在目录下了)
- tar 解压
- make && make install
那么,我们只需要下载你需要的版本的 beanstalkd 压缩包到,再解压,再编译安装,就行了。
这里,记录一下我安装的过程:
1 | wget https://github.com/beanstalkd/beanstalkd/archive/v1.10.zip |
最后一个命令执行之后如果能够反馈给你 beanstalkd 的版本号,说明安装成功了,接下来就是启动 beanstalkd 的服务:
1 | beanstalkd -l 0.0.0.0 -p 11300 -b /log/beanstalkd/binlog -F |
-l 指绑定的 ip ,默认为 127.0.0.1
-p 指绑定的端口,默认端口 11300
-b 指开启 binlog 进行持久化,用于断电后恢复数据
-F 不把内存文件写入磁盘
更多的选项,可以通过 beanstalkd -h 查看
当然,你还可以直接使用 yum 或者 apt-get 来安装,更加方便。
如果重复运行 beanstalkd -l -p 的命令,可以让 beanstalkd 同时监听多个 ip 和端口。
默认情况下,我们的 beanstalkd 没有开启 binlog 的功能,且绑定的 ip 为 127.0.0.1 ,网上有很多文章说,如果安装 web 控制台的时候,无法连接 beanstalkd ,就把 127.0.0.1 改成 0.0.0.0 ,这是不对的。
这个 ip 是指 beanstalkd 监听(允许连接)的客户端,比如你的客户端 ip 为 155.22.98.28 ,此时,你设置 -l 为该 ip , 则,该 ip 可以访问 beanstalkd 的服务器。
如果改成 0.0.0.0 ,指不限制,那么,你的 beanstalkd 服务器就非常危险,任何 ip 都能访问进来。
这里,必须要知道一下,为什么改成 0.0.0.0 就可以访问了。
你可能需要根据你的部署架构来综合分析,如何设置这个 ip ,并理清你的内外网、物理机、虚拟机,这样才能设置最合理的 ip 。
另外,在部署环境里,如果非要设置 0.0.0.0 (均衡负载的情况下可能有多个客户端连接过来),此时,就需要通过网络环境上的 ip 白名单、端口等方式来过滤。
总的来讲,beanstalkd 的服务器没有一个账号密码体系,只有监听 ip 的方式,来鉴别它是否处理你的指令。所以,它非常纯洁,如果我们需要最大程度上控制安全,最好让 beanstalkd server 只允许本机访问,而外部则访问位于本机上的 client ,由 client 进行安全校验和连接 beanstalkd server 。
六、beanstalkd 使用(PHP)
阿里云使用
1 | 查看端口号是否被占用 |
Pheanstalk
1 |
|
七、什么是消息队列
以下主要搬运下面这个链接的消息,请去原文观看
https://www.kancloud.cn/vson/php-message-queue/885553
几个名词
- 消息
消息( Message ),在计算机底层,是一种数据传输单位。 - 队列
队列( Queue ),一种数据结构,具有先进先出、有先后顺序的特性。 - 消息队列
消息队列( Message Queue , MQ ),一种队列结构的存储中间件,即,它本身是一个存储容器,而内部数据的存放结构是队列。 - 生产者
生产者( Producer ),它生成消息,并将消息存入消息队列中。 - 消费者
消费者( Consumer ),它从消息队列中取出消息,进行处理,处理完成之后,该消息从队列中删除。有些地方也会叫做订阅者。
八、消息队列的应用场景
数据冗余
我们可能在看到“冗余”这个词的时候,觉得他是个贬义词。
但实际上,一定程度的冗余,会让我们的数据更加安全。
比如,数据库备份,就是一种数据冗余,mysql读写分离,亦是通过日志和轮询实现数据冗余。
这样,当我们某一份数据出现问题时,我们还有第二份数据,数据就更加安全。
那么,消息队列如何提供冗余功能呢?
常见的消息队列系统,会将数据保存在内存中,以提高数据读写效率。既然数据在内存中,就可能出现丢失的情况,所以,它们又提供持久化的功能,保证在队列系统崩溃后,数据仍然存在。
另外,消息队列内的每一条消息,都必然存在 reserved 和 deleted 两个状态,只有当消费者给队列系统发送处理成功的信号时,消息才会从队列中删除,并不会因为消息已接收,就删除消息。
可以说,消息队列,也是增对数据库层的一道输入向缓存,对数据有冗余作用。即,当有数据需要进入数据库,会先经过消息队列,再进入数据库。
解耦合
我们知道软件工程讲究高内聚低耦合,所以我们会想许多办法来控制耦合度,即解耦。
消息队列,也是一种解耦的方案。
按照普通流程,消费代码可能会直接跟在生产代码后面,那么,生产和消费就成了彼此的上下文,甚至连变量、作用域等都会有依赖,此时,你若对生产代码的某个变量进行修改,你必须仔细检查消费代码是否也使用了这个变量。
通过消息队列,我们将生产代码和消费代码拆分开来,它们不再互相依赖彼此的具体实现,只依赖于消息队列中消息的结构。只要消息结构不变,生产代码和消费代码如何修改,都不会影响到彼此。
这一点,我们可以联想到上一章《什么是消息队列?》中的下单功能辅助理解。
异步能力
有人说,高性能离不开异步,异步离不开队列。
一定意义上来说,这句话是很有道理的。
异步,它让每一个调用都能及时返回,提升响应速度。队列,保证了异步调用的处理不会丢失。这句话中的“处理”一词,指处理工作,是个名词。
我们知道,异步,它先返回的是调用动作是否成功的结果,而具体调用执行的逻辑和结果,并不在这里返回,而是以通知(回调)的形式进行。队列,是确保每一个调用的处理都会被执行数据结构。
这一点,我们可以在之后消息队列的实践中,体会到。
消息队列,能够让在架构上提供异步能力(注意,是架构上,而非代码层面如函数调用的异步能力)。
关于这个异步能力,还是可以参考上一章《什么是消息队列?》中的下单功能,
扩展性
当架构中加入消息队列,生产者和消费者就比较容易扩展。
仍然以下单功能举例,如果生产者和消费者的代码耦合在一起,互相严重依赖,当我们想对生产者产生内容进行不同的处理(消费)时,则需要在原有的源码中进行扩展,这对原有代码产生伤害,便不必说扩展性了。
但如果以消息队列将生产者和消费者进行解耦,则,我们只需要添加订阅消息的消费者程序即可,新的消费者对旧消费者没有任何伤害,它依旧依赖于消息队列,只需要确保它能收到消息即可。
顺序保证
队列本身具备“先进先出”的特性,消息队列是一种队列结构的中间件,则,消费者会根据消息进入的先后顺序,进行先后处理。
其本身就能解决顺序问题
削峰填谷
在某些高并发的场景下,流量突然激增,比如秒杀。
此时,数据库的压力很大,而数据库的读写处理能力普遍低于内存式的消息队列。
此时,可以将消息临时存储于消息队列中,减少数据库的压力,然后再由消费者按数据库能够接受的频率去读取消息,进行处理,因为数据库只在秒杀那一刻压力很大,平时会清闲一些。
这就是将山峰削掉,填补山谷
九、消息队列的注意事项
复杂度
最简单的架构可能只有 PHP+MYSQL ,此时,复杂度是低的。
我们遇到问题,需要考虑的可能性也会较少,需要检查的部件也比较少。
而当我们开始使用消息队列,我们自然而然需要考虑到消息队列的相关信息,复杂度,自然提升了。
当然,这可能无法避免。
比如,生活中,我们使用电风扇,可以吹到凉风。但如果我们还需要制热,就会购买空调。电风扇若是坏了,我们或许能自己修回去,但若是空调坏了,我们可能需要有一定专业知识,才能修理。这就是复杂度。
当能力变强的同时,复杂度也会提升,这一点通常无法避免,除非,我们找到更多的方案,再分析方案间的利弊,最后决策
可用性
因为生产者和消费者都依赖于消息队列,比如订单系统使用了消息队列,那么,我们需要考虑到消息队列的可用性,消息队列一旦崩溃,订单系统便不能正常运转,而任何依赖于订单系统的功能,也将无法提供服务。
虽然,消息队列出现崩溃的概率相对较低,但在选型初期和设计架构的时候,还是要充分考虑,并尽可能设计好预备方案。
一般而言,常见的消息队列系统,会通过分布式来提高可用性。
消息可靠性
在消息队列使用过程中,我们可能会遇到这种情况:
生产者将消息发出,但消息队列没有接收到
这很可能是网络原因,比如,生产者发出消息,但由于网络或者消息队列方面的一些原因,最终,消息没有被存入指定的队列中,此时,可能引起消息丢失。一般我们会要求消息队列返回一个确认信息,告诉生产者,消息放好了。如果,生产者迟迟未能接收到确认信息,则再次发送消息。以此来保证消息不被丢失。
消息队列崩溃或服务器宕机,内存清空,数据丢失
当遇到这种情况,会导致其存储在内存中的数据丢失,消息的可靠性就得不到保证。一般我们会通过持久化来保证消息不丢失,不同的消息队列系统,持久化的方式未必一样,具体的使用,将会在后面章节详细介绍。
消费者崩溃,无法正确处理消息
还有一种情况,当消费者从消息队列中读取出消息,消息状态变成了 reserved 或者,干脆直接在队列中被删除,而此时,消费者却在执行后面的程序时崩溃了,导致业务流程没有顺利执行,但消息已经被取出。
这也是一种数据丢失的现象。一般此时,也需要消费者与消息队列之间建立反馈机制,一定要当在消费者处理完消息之后,给消息队列发送明确的删除指令,才能删除消息。
另外消息队列这边,可以建立 TTR( time-to-run , 超时重发)机制,如果队列中处于 reserved 状态的消息过了一定时间还未被删除,可以将之丢回 ready 状态,继续被消费者读取
顺序消费
首先,顺序消费和顺序保证,是两回事
顺序保证是指同类型的消息被消费的先后顺序,而顺序消费,是指,当一个消息,需要被多个消费者按一定顺序先后消费。
例如,当消息队列中存放一个订单信息时,我们有以下消费者:
- 发短信
- 发邮件
- 发 APP 推送
而我们必须先发短信、再发邮件、再发 APP 推送,不可提前,不可押后。
这就是一种顺序消费的场景。
一般来讲,有两种比较常见的解决方案:
合并消费者
这种方式一般不推荐,但前期实现起来复杂度较低。
它意味着将多个消费者合并为一个消费者,再顺序执行。
虽然可以实现逻辑,但本身却降低了可扩展性,提高了耦合,这对未来维护项目而言,会增加隐性成本。控制消费状态
还有一种方案,我们在生产者中放入短信消息,当短信消息被处理完后,在消费者中往邮件队列放入消息,以此类推。
但这也会引起问题,比如,当我们将短信—>邮件—>推送串联好,但我们又要在短信和邮件之间,插入一个新的消费者,此时,我们除了要新增消费者以外,还需要修改短信消费者。
这种设计就像是一个链表,头是生产者,指向短信,短信指向邮件,此时中间插入一个,需要将短信原本指向邮件的指针,指向新的消费者,而新的消费者则指向邮件。
消息重复
前面有说过,为了保证消息可靠性,我们可能会让生产者重复发送消息(当迟迟没有收到消息队列反馈的时候)。
但是,这种情况,大多数时候是由网络不稳定引起的。
也就是说,虽然消息队列的反馈,可能迟到,但并不代表,消息已经丢失了。
此时,生产者再次往消息队列发送消息,则消息队列可能会收到两条重复的消息。
这里举个例子:比如消费者需要为用户余额加 5 元钱,如果消息重复,就有可能为用户加上好几个 5 元。
我们一般通过保证消费者被重复执行的幂等性来避免消息重复带来的问题。
幂等性指:多次进行同样的操作,执行结果都一致
比如,你输入的数据在不变的情况下,你的算法应保证处理结果是一致的,特别是在业务逻辑上。
为什么要通过保证消费者的幂等性来避免消息重复?
因为我们无法保证,网络不出现拥堵,不出现故障。
所以,我们无法保证,生产者不重复往队列中写入消息。
因此,比较好的方案,是在消费者上面进行控制。
比如,幂等性能够保证,同样一条消息,尽管被消费者读取多次,但在现实中产生的影响,却只有一次。
至于如此保证幂等性,会是一个比较复杂的问题,我们需要根据项目的实际情况和实际架构,进行具体的设计。
一致性
因为消息队列赋予了异步能力,所以,当我们生产者在调用的时候,并非业务逻辑已经成功执行完。
比如,我们在生产者中调用发短信,实际上,短信并未发出去,只是将要发短信的任务存储到队列中,等到被执行。
那么,此时给调用返回的结果,只是调用的结果,并不等于发送成功。
所以,我们无法以调用结果来判定业务处理结果。
这个就是暂时不一致性。
这个结果,暂时的,与你所知的不一致。
但,它最终会一致,也就是说,最终,消息队列内的每一条消息都会被取出来消费。
这个就是最终一致性
十、beanstalkd 协议翻译
协议描述
beanstalkd 协议 运行在 TCP 层上,并采用了 ASCII 编码。
大致工作流程为:开启客户端连接、发送命令和数据、等待响应、关闭连接。
对于每一个连接而言,服务器会按照接收到指令的顺序一一执行这些指令,并且按照同样的顺序,发送响应。
在本协议中,所有涉及到的整数,都是指十进制,且为非负,除非另有说明。
命名约定
只支持 ASCII 字符进行命名
其支持的字符有:
- 字母( A-Z、a-z )
- 数字( 0-9 )
- 小短横( - )
- 加号( + )
- 正斜杠( / )
- 英文封号( ; )
- 英文点号( . )
- 美元符( $ )
- 英文下划线( _ )
- 英文左右小括号( “(“ 和 “)” )
注意:命名不可以 - 作为开头,当遇到空格或换行时,会视作命名结束。每个命名的长度,至少为 1+ 个字符。
Errors
| 错误类型 | 描述 |
|---|---|
| OUT_OF_MEMORY\r\n | 服务器内存不够分配了,可能需要过一会再尝试 |
| INTERNAL_ERROR\r\n | 这说明服务器,也就是 beanstalkd 内部出现了 bug ,理论上不应该出现这个错误,如果出现了,请将这个 bug 提交到 google group |
| BAD_FORMAT\r\n | 发送的命令格式错误。比如,命令行不是以 \r\n 结尾,又或者在该传入数值的地方传入了非数值,也可能参数数量错误等一切命令格式有误的可能性。 |
| UNKMOWM_COMMAND\r\n | 使用了未定义的命令(找不到这个命令),此时可能要检查是否拼写有错 |
Job 生命周期
一个 Job 由 put 命令创建,在它的生命周期以内,它必将处于以下四种状态中的一种:「ready」、「reserved」、「delayed」、「buried」
当使用完 put 命令,Job 一般从 「ready」 开始,它会在「ready」队列中等待,直到有「reserved」命令过来,当接收成功之后,则将该 Job 放入到 「reserved」 队列。接着,当进程处理完这个 Job 之后,则会发送一个「delete」命令,将这个 Job 从 beanstalkd 中删除。
| 状态 | 描述 |
|---|---|
| ready | 被放入 Tube 之后等待被接收和处理 |
| reserved | 当 Job 被 reserve 命令接收,Job 会进入这个状态,它代表被接收,但还没有得到其他反馈 |
| delayed | 延迟状态,等时间到了会变成 ready 状态 |
| buried | 预留状态,一般当消费者处理失败时,会将它设置为预留 |
图示 Job 生命周期:
1 | put reserve delete |
当然,它也可能经历更复杂的演化,如下图:
1 | put with delay release with delay |
Tubes
一个 beanstalkd 服务允许拥有多个 Tube ,每一个 Tube 包含两个队列: ready queue 和 delay queue 。
每个 Job 都必然会存在于某个 Tube 之下。
可以通过 watch 指令关注某个 Tube ,也可以通过 ignore 命令取消关注。
当你使用 watch list 命令时,它会返回你所关注的 tubes 。
当消费者开始接收 Job 的时候,Job 一般来自 watch 了的 Tube。
当一个客户端连接进来,watch list 最初只有一个名为 default 的 tube 。如果当存入 Job 时没有使用 use 命令指定 tube ,这个 Job 就会被放入到 default tube 中。
Tubes 会在你使用到它的时候创建,如果 Tube 变空了(没有 ready Job ,没有 delayed Job , 没有 buried Job),且没有客户端连接指向它,它就会被删掉。
生产者命令
put
此命令用于向队列中插入 job ,命令格式如下:
1 | put <pri> <delay> <ttr> <bytes>\r\n |
它默认会将 job 插入到当前所 use 的 tube , 这点可以参考下面的 use命令
| 选项 | 描述 |
|---|---|
| pri | 这是一个整型数值,代表着这个 job 的优先级,数值越小,排队排在越前面,优先级最高为 0 ,最后面为 4294967295 |
| delay | 这也是一个整型数值,是一个秒数,指多少秒之后将这个 job 放入到 ready queue 中,在那之前,这个 job 都将处于 delayed 状态 |
| ttr | 这也是一个整型数值,是一个描述,指一个 job 被允许处理的最大时间,这个时间从 job 被 reserve 起开始计算,超过时间还未被 delete 、 release 、 bury ,则服务器会自动释放这个 job,并重新插入到 ready queue 中。此数值最小支持 1 ,如果传的是 0 ,则服务器会默认将它变成 1 |
| bytes | 这是一个数值,用于指明这个 job body 的大小,不包含「\r\n」这两个字符。这个值必须小于 beanstalkd 配置的 max-job-size , 单位是 bytes |
| data | 这是 job body ,上一行的 bytes 就是由此行除却「\r\n」计算得出的。 |
当成功发送 put 命令后,客户端要等待响应,响应结果可能是如下几个:
| 响应 | 描述 |
|---|---|
| INSERTED \r\n | 插入成功,id 是一个 interger ,标识新插入的 job |
| BURIED \r\n | 如果服务器因为增加优先级队列而内存不足时会返回这个结果,id 是一个 interger ,标识新插入的 job |
| EXPECTED_CRLF\r\n | job body 必须以「\r\n」结尾,这两个字节不用计入上一行的 bytes 计算中 |
| JOB_TOO_BIG\r\n | job body 超出了 max-job-size 的限制 |
| DRAINING\r\n | 目标服务器不再接收新的请求,需要尝试其他服务器,或断开连接之后晚点再重新尝试 |
use
此命令为 Producer 提供,当发送此命令之后,后续的 put 命令,就会把 job 全部放入到此 use 命令指定的 tube 中。如果没有通过 use 指定 tube , 则会默认将 job 放入到 default tube 中。
1 | use <tube>\r\n |
| 选项 | 描述 |
|---|---|
| tube | 一个最大不超过 200 bytes 的名称,它指定一个 tube ,如果这个 tube 不存在,则会自动创建 |
| 响应 | 描述 |
|---|---|
| USING \r\n | 是接下来开始使用的 tube |
消费者命令
从 queue 中消费 job 会使用以下命令:
- reserve
- delete
- release
- bury
reserve
1 | reserve\r\n |
另外,你还能指定接收的超时时间,如下:
1 | reserve-with-timeout <seconds>\r\n |
这个命令将会返回一个新的、reserved 状态的 job
如果没有可用的 job 能被接收,则 beanstalkd 一直等到出现一个可接收的 job 之后再返回。
一旦一个 job 被客户端接收,客户端要在 ttr 指定的时间限定内处理 job ,否则,超时的话,服务器会将 job 重新放回 ready queue 中。
可以在 stats-job 命令的 response 中找到 ttr 的值和已经使用掉的时间。
如果处于 ready 状态的 job 不止一个,beanstalkd 将会选择一个 priority 最小的 job,如果 priority 相等,则会选择一个最先 put 的 job 。
题外话:这里我怀疑 beanstalkd 的协议有一处写错了,原文为 Within each priority, it will choose the one that was reserved first. 我认为应该将 reserved 改为 put 。
如果指定的 timeout seconds 是 0 ,这将导致服务器立即返回 TIME_OUT 的响应(也有可能立即返回一个 job ,这取决于服务器的响应速度以及是否存在可接收的 job )
为 timeout 设置一个合理的 seconds ,可以限制客户端阻塞等待接收 job 的时间。
| 失败响应 | 描述 |
|---|---|
| DEADLINE_SOON\r\n | ttr 的最后一秒,被服务器设定为安全界限,在此期间,该客户端不会接收到另外一个 job 。比如:客户端在安全界限时间里发送了一条 reserve 命令,或者,当一条 reserve 命令在等待反馈时,安全界限时间正好到期,这时候,都将得到一个 DEADLINE_SOON\r\n 的响应 |
| TIMED_OUT\r\n | 当使用 reserve-with-timeout 命令,超过时间还未接收到 job ,又或者客户端连接已经关闭,此时会返回此值 |
成功响应:
1 | RESERVED <id> <bytes>\r\n |
| 参数 | 描述 |
|---|---|
| id | job 的 id ,一个整型值,在这个 beanstalkd 服务器中具备全局唯一性 |
| bytes | 表示 job data 的大小,不包含结束符 \r\n |
| data | job data , 之前 put 时放入的 job data ,原模原样返回 |
delete
delete 命令用于从服务器完全删除一个 job , 这一般用于客户端成功处理 job 之后。
客户端可以删除 reserved 的 job , 使 job 进入准备状态 , 延迟 job ,预留 job 。
1 | delete <id>\r\n |
| 选项 | 描述 |
|---|---|
| id | job 的 id |
| 响应 | 描述 |
|---|---|
| DELETED\r\n | 删除成功 |
| NOT_FOUND\r\n | 找不到这个 job ,或者这个 job 并非这台 client 接收的、或是 job 处于 ready 、 buried 状态。这很可能发生在 ttr 时间到了之后才发送 delete 命令的情况下。 |
release
此命令可以把 reserved job 放回 ready 队列中,同时 job 的状态也会回到 ready ,release 之后,这个 job 可以被任何其他的客户端接收。
一般这个命令用在消费者处理 job 失败的情况下。
1 | release <id> <pri> <delay>\r\n |
| 选项 | 描述 |
|---|---|
| id | job id |
| pri | interger ,指定一个新的优先级,数值越小,越早被接收 |
| delay | interger ,指定一个新的延迟,如果设置了预留值,则 job 的状态会是 delayed ,直到延迟时间到期 |
| 响应 | 描述 |
|---|---|
| RELEASED\r\n | 处理成功 |
| BURIED\r\n | 因为新增优先级队列数据结构而导致内存溢出 |
| NOT_FOUND\r\n | 没有找到这个 job 或 此 job 不是当前客户端接收的 |
bury
这个命令可以将一个 job 操作为 buried 状态。
buried job 被存放在一个 FIFO (first input first out ,先进先出)的链表中,它不会被服务器再次操作,除非有客户端对它发起了 kick 命令。
1 | bury <id> <pri>\r\n |
| 选项 | 描述 |
|---|---|
| id | job id |
| pri | 优先级,一个整型数字,越小的越先被接收 |
| 响应 | 描述 |
|---|---|
| BURIED\r\n | 操作成功 |
| NOT_FOUND\r\n | 找不到 job 或该 job 不是被当前客户端所接收 |
touch
此命令能让当前消费者得到更多的执行 job 的时间。
比如,ttr 是用于避免消费者崩溃而导致 job 丢失,但同样也会误伤一批执行时间过长的消费者,实际上消费者没有崩溃,但执行时间已经超出了 ttr ,此时,通过 touch 命令,可以让客户端得到更多的处理时间,不先触发 ttr 机制。
当然,使用了 touch 命令,只是延长了 ttr 的时间,ttr 的机制仍然存在。
通过这个命令,消费者可以定期告诉服务器,当前处理程序仍处于活跃状态。
此命令不受 DEADLINE_SOON影响
1 | touch <id>\r\n |
| 选项 | 描述 |
|---|---|
| id | job id |
| 响应 | 描述 |
|---|---|
| TOUCHED\r\n | 操作成功 |
| NOT_FOUND\r\n | 没有找到这个 job 或者 该 job 不是这个客户端接收的 |
watch
watch 命令会往 watch list 中添加一个 tube ,消费者通过 reserve ,可以接收到 watch list 中任何一个 tube 传来的 job 。一个新的连接,watch list 中默认存在一个 default tube 。
1 | watch <tube>\r\n |
| 选项 | 描述 |
|---|---|
| tube | 200 bytes 以内的字符串,代表着 tube 的名字,如果该 tube 不存在,则会自动创建 |
返回响应:
1 | WATCHING <count>\r\n |
conut 是一个数值,指当前 watch list 中有多少 tube 。
ignore
此命令用于从 watch list 中移除一个 tube ,移除之后,该消费者不再接收被移除的 tube 内的 job 。
1 | ignore <tube>\r\n |
| 选项 | 描述 |
|---|---|
| tube | 200 bytes 以内的字符串,代表着 tube 的名字,如果该 tube 不存在,则会自动创建 |
| 失败响应 | 描述 |
|---|---|
| NOT_IGNORED\r\n | 如果当前 watch list 中只存在最后一个 tube,则会返回这个响应 |
成功响应:
1 | WATCHING <count>\r\n |
conut 是一个数值,指当前 watch list 中有多少 tube 。
其他命令
peek
用于客户端检查 job ,此命令有四种形态,除了第一个操作以外,其它操作都只针对于当前的 tube 。
1 | peek <id>\r\n 根据 id 返回一个 job |
| 失败响应 | 描述 |
|---|---|
| NOT_FOUND\r\n | 找不到 job 或没有该状态的 job |
成功响应:
1 | FOUND <id> <bytes>\r\n |
其中,id 为 job 的 id ,bytes 指 data 的大小(不包含 \r\n ),data 是 job 的具体内容
kick
此命令只适用于当前指定的 tube 。
此命令能将 job 状态改成 ready , 它需要传入一个数字,用于指定需要修改多少个 job 。
比如,你传入 10 ,则会将队列中十个 buried 或 delayed 状态的 job ,修改为 ready 。
如果,指定的队列中存在 buried job ,则只会修改 buried job,否则,就修改 delayed job 。
1 | kick <bound>\r\n |
| 选项 | 描述 |
|---|---|
| bound | 指定要 kick 多少 job |
响应:
1 | KICKED <count>\r\n |
count 表示该操作成功修改了几个 job 。
kick-job
这是一个 kick 扩展命令,用于将单独的一个 job 修改为 ready 。它需要传入一个 job id 。
如果传入的 job id 所代表的 job 在当前 tube 中存在,并且该 job 的状态处于 buried 或 delayed ,则会将这个 job 设置为 ready ,并仍然在当前 tube 中。
1 | kick-job <id>\r\n |
| 选项 | 描述 |
|---|---|
| id | job id |
| 响应 | 描述 |
|---|---|
| NOT_FOUND\r\n | job 不存在或不处于可 kick 的状态,另外,这也可能发生在内部错误上 |
| KICKED\r\n | 操作成功 |
stats-job
此命令用于查看一个 job 的统计信息
1 | stats-job <id>\r\n |
| 选项 | 描述 |
|---|---|
| id | job id |
| 错误响应 | 描述 |
|---|---|
| NOT_FOUND\r\n | job 不存在 |
成功响应:
1 | OK <bytes>\r\n |
bytes 指后面 data 的大小,data 则是该 job 的统计信息,是一个 YAML 格式的文本。
data 包含以下 key :
| key | 描述 |
|---|---|
| id | job id |
| tube | 此 job 所在的 tube |
| state | job 的状态 |
| pri | job 的优先级 |
| age | job 在队列中存在的时间,是一个秒数 |
| time-left | 此 job 距离被放入 ready queue 的剩余秒数,这个时间到达之后,此 job j就会被放入到 ready 队列。此参数只在 job 状态为 reserved 和 delayed 时有意义,当状态为 reserved 时,此参数代表 job 的超时剩余秒数,即 ttr |
| file | 此 job 的 binlog 序号,如果未开启 binlog ,则此值为 0 |
| reserved | 此 job 被 reserve 的次数 |
| timeouts | 此 job 的超时次数 |
| releases | 此 job 被 released 的次数 |
| buries | 此 job 被 bury 的次数 |
| kicks | 被 kicked的次数 |
stats-tube
此命令返回 tube 的统计信息,如果这个 tube 存在的话。
1 | stats-tube <tube>\r\n |
| 选项 | 描述 |
|---|---|
| tube | 传入 tube 的名称 |
| 失败响应 | 描述 |
|---|---|
| NOT_FOUND\r\n | 不存在这个 tube |
成功响应:
1 | OK <bytes>\r\n |
bytes 是指 data 的大小,不包含 「\r\n」。
data 是一个 YAML 格式的文本,它包含了你想要的 tube 的统计信息
下面是 data 的 key :
| key | 描述 |
|---|---|
| name | tube 的 name |
| current-jobs-urgent | 这个 tube 中,优先级小于 1024 的 ready job 数量 |
| current-jobs-ready | 这个 tube 中的 ready job 数量 |
| current-jobs-reserved | 这个 tube 中被 reserve 的 job 数量,不论它是被哪个消费者接收的 |
| current-jobs-delayed | 这个 tube 中处于 delayed 状态的 job 数量 |
| current-jobs-buried | 这个 tube 中处于 buried 状态的 job 数量 |
| total-jobs | 此 tube 一共创建过几个 job |
| current-using | 指向此 tube 的连接数量 |
| current-waiting | 指向此 tube 并且处于接收等待状态、但还未接收到 job 的连接数量 |
| current-watching | watch 了此 tube 的连接数量 |
| pause | 此 tube 停止服务的秒数 |
| cmd-delete | 此 tube 累计执行了几次 delete |
| cmd-pause-tube | 此 tube 累计执行了几次 pause-tube |
| cmd-time-left | 此 tube 几秒之后提供服务 |
stats
此命令返回整个服务器系统的统计信息。
1 | stats\r\n |
成功响应:
1 | OK <bytes>\r\n |
bytes 是指 data 的大小,但不包括 「\r\n」。
data 是一个 YAML 文本,包含了如下 key :
| key | 描述 |
|---|---|
| current-jobs-urgent | 优先级小于 1024 的 ready job 数量 |
| current-jobs-ready | ready job 的数量 |
| current-jobs-reserved | 被接受的 job 数量,不区分客户端(消费者) |
| current-jobs-delayed | delayed job 的数量 |
| current-jobs-buried | buried job 的数量 |
| cmd-put | 累积执行 put 的次数 |
| cmd-peek | 累积执行 peek 的次数 |
| cmd-peek-ready | 累积执行 peek-ready 的次数 |
| cmd-peek-delayed | 累积执行 peek-delayed 的次数 |
| cmd-peek-buried | 累积执行 peek-buried 的次数 |
| cmd-reserve | 累积执行 cmd-reserve 的次数 |
| cmd-use | 累积执行 use 的次数 |
| cmd-watch | 累积执行 watch 的次数 |
| cmd-ignore | 累积执行 ignore 的次数 |
| cmd-delete | 累积执行 delete 的次数 |
| cmd-release | 累积执行 release 的次数 |
| cmd-bury | 累积执行 bury 的次数 |
| cmd-kick | 累积执行 kick 的次数 |
| cmd-stats | 累积执行 stats 的次数 |
| cmd-stats-job | 累积执行 stats-job 的次数 |
| cmd-stats-tube | 累积执行 stats-tube 的次数 |
| cmd-list-tubes | 累积执行 list-tubes 的次数 |
| cmd-list-tube-used | 累积执行 list-tube-used 的次数 |
| cmd-list-tubes-watched | 累积执行 list-tubes-watched 的次数 |
| cmd-pause-tube | 累积执行 pause-tube 的次数 |
| job-timeouts | 累积 timeout 的 job 总数 |
| total-jobs | 累积创建了几个 job |
| max-job-size | 最大允许的 job 字节数 |
| current-tubes | 当前有几个 tube |
| current-connections | 当前有几个连接 |
| current-producers | 当前有几个至少发出过一条 put 指令的连接 |
| current-workers | 当前有几个至少发出过一条 reserve 指令的连接 |
| current-waiting | 当前有几个至少发出过一条 reserve 指令但还未接收到 response 的连接 |
| total-connections | 累积有过几个连接 |
| pid | 服务器的进程 id |
| version | 当前服务器的版本 |
| rusage-utime | 进程占用用户 cpu 的时间,分别有「秒」和「微秒」的单位 |
| rusage-stime | 进程占用系统 cpu 的时间,分别有「秒」和「微秒」的单位 |
| uptime | 此进程已运行的秒数 |
| binlog-oldest-index | 最早存储的 job binlog 索引号 |
| binlog-current-index | 当前的 job binlog 索引号,新的 binlog 会从这里开始写入,如果未开启 binlog ,此值为 0 |
| binlog-max-size | 每个 binlog 文件允许分配的最大容量,单位 bytes |
| binlog-record-written | 写入 binlog 的累积次数 |
| binlog-records-migrated | 以压缩形式写入 binlog 的累积次数 |
| id | 一个随机字符串,用于标记这个进程,在 beanstalkd 开启时生成 |
| hostname | 主机名,由 uname 决定 |
上面这些 key 的信息,自从 beanstalkd 启动以来就开始累积,如果重启,就会重新累积。另外,这些数据不存放在 binlog 中
list-tubes
此命令返回所有存在的 tube 。
1 | list-tubes\r\n |
成功响应:
1 | OK <bytes>\r\n |
bytes 是指 data 的大小,不包含「\r\n」。
data 返回一个 YAML 字符串,里面包含了 tube 的列表。
list-tube-used
此命令返回当前所 use 的 tube 。
1 | list-tube-used\r\n |
成功响应:
1 | USING <tube>\r\n |
tube 是指当前 use 的 tube 名字。
list-tubes-watched
此命令用于查看当前客户端 watch-list 中的 tube 。
1 | list-tubes-watched\r\n |
成功响应:
1 | OK <bytes>\r\n |
bytes 是指 data 的大小,不包含「\r\n」。
data 是一个包含了 tube list 的 YAML 字符串。
quit
此命令用于关闭当前连接。
1 | quit\r\n |
pause-tube
此命令为某个 tube 指定一个时间,在这个时间内,此 tube 内的 job 将不会被 reserve 。
1 | pause-tube <tbe-name> <delay>\r\n |
| 选项 | 描述 |
|---|---|
| tube | tube 的名字 |
| delay | 指定一个秒数 |
| 响应 | 描述 |
|---|---|
| PAUSED\r\n | 操作成功 |
| NOT_FOUND\r\n | 没有这个 tube |
十、Beanstalkd 关键命令表格
| 命令 | 描述 |
|---|---|
| put | 在队列中生成 job |
| use | 用于生产者指定后续要存放 job 的 tube |
| reserve | 用于消费者从队列中预定一个 job (接收 job),此命令会阻塞控制台,直到接收到 job |
| reserve-with-timeout | 接收 job ,附带超时时间,超过时间未接收到 job 就结束了 |
| delete | 删除一个 job |
| release | 将一个 reserved job 放回 ready 队列 |
| bury | 将一个 job 操作为 buried |
| touch | 延长一个 job 的 ttr |
| watch | 将一个 tube 加入到 watch list ,只有加入到 watch list 的 tube 才会被 reserve 命令接收到 job |
| ignore | 从 watch list 中移除 tube |
| peek | 根据 id 返回一个 job ,纯返回,不会修改 job 的状态 |
| peek-ready | 返回当前 tube 的一个 ready job |
| peek-delayed | 从当前 tube 中返回一个剩余延迟时间最短的 delayed job |
| peek-buried | 从当前 tube 中返回下一个 buried job |
| kick | 一次性修改多个非 ready 的 job 到 ready 状态,其中会先处理 buried 再处理 delayed |
| kick-job | 将指定的 job 调整为 ready 状态,调整后仍在原 tube 内 |
| stats-job | 查看某 job 的统计信息 |
| stats-tube | 查看某 tube 的统计信息 |
| stats | 查看 beanstalkd 的统计信息 |
| list-tubes | 返回当前存在的所有 tube |
| list-tube-used | 查看当前 use 的 tube |
| list-tubes-watched | 查看当前 watch list 中的 tube |
| quit | 关闭当前连接 |
| pause-tube | 暂停 tube ,暂停后,tube 内的 job 不会再被接收 |
十一、Pheanstalk 协议解析
PheanstalkInterface
这是一个连接实例的接口。
它定义了一个 beanstalkd 连接必须拥有的方法。
常量
| 常量 | 描述 |
|---|---|
| DEFAULT_PORT = 11300 | 默认连接端口号 |
| DEFAULT_DELAY = 0 | 默认延迟秒数,0 为不延迟 |
| DEFAULT_PRIORITY = 1024 | 默认优先级,0 为最高优先级 |
| DEFAULT_TTR = 60 | 默认 TTR 60秒 |
| DEFAULT_TUBE = ‘default’ | 默认 tube |
方法
| 方法 | 用途 |
|---|---|
| bury | put 一个 buried job ,只有在 kick 后才能被 reserve |
| delete | 永久删除一个 job |
| ignore | 从 watchlist 中移除一个 tube |
| kick | 移动指定数量的 buried 或 delayed job 到 ready 对列中,有buried 会先处理 buried |
| kickJob | 将单个 job 移动到 ready 队列中,移动后仍处于该 tube |
| listTubes | 当前 server 的所有 tube |
| listTubesWatched | 查看当前 watchlist,可通过传入 true 还是 false ,来要求是从服务器获取,还是从缓存获取 |
| listTubeUsed | 当前 use 的 tube ,传入 true , 则从服务器请求,传入 false ,则使用上一次的结果(缓存) |
| pauseTube | 暂时不让 tube 内的 job 被 reserve |
| resumeTube | 恢复被暂停的 Tube |
| peek | 查看一个 job ,不论它处于什么 tube |
| peekReady | 查看 ready 队列中下一个可被 reserve 的 job (当前 tube 中) |
| peekDelayed | 查看 delayed 队列中下一个即将进入 ready 的 job (当前 tube 中) |
| peekBuried | 查看下一个 buried job (当前 job 中) |
| put | 放入一个 job |
| release | 把一个 reserved job 重新放回 ready 队列 |
| reserve | 从当前 watchlist 中锁定一个 job (接收一个 job) |
| reserveWithTimeout | 有超时时间的 reserve |
| statsJob | 查看一个 job 的统计信息 |
| statsTube | 查看一个 tube 的统计信息 |
| stats | 查看 server 的统计信息 |
| touch | 为 job 延长一次 ttr |
| useTube | use 一个 tube ,用于接着 put job |
| watch | 把一个 tube 加入到 watchlist |
| watchOnly | 往 watchlist 中加入一个 tube ,并 ignore 其他所有 tube |
JobIdInterface
方法
| 方法 | 描述 |
|---|---|
| getId | 获得 Job 的 id |
CommandInterface
pheanstalk 的设计中,每个 beanstalkd 命令都以一个类的形式呈现,想要向 beanstalkd server 发送命令,需要通过实例化各 command 类来实现。
CommandInterface 接口,是所有 command 类最抽象的形态,我们观察 pheanstalk 的源码,可以发现,AbstractCommand 抽象类实现了这个接口。
而 AbstractCommand 又会被 TubeCommand 、JobCommand 类继承,再往下,还会有具体的命令 command 类继承 Tube 和 Job command 类。
由此,我们也可以看出 pheanstalk 在代码设计上的思路:从 CommandInterface ,到 AbstractCommand ,再到 TubeCommand、JobCommand , 再到具体的命令 command ,它们便是一个典型的从抽象到具体的过程。
在此,我们可以再回去看看 beanstalkd 的协议,熟悉各种命令和用途,结合 pheanstalk 对 command 的封装过程,以提升我们在面向对象上的设计能力。
要求每一个 command 类都必须实现以下几个方法,且拥有以下几个常量。
常量
CommandInterface 的常量格式为 COMMAND_* ,如 COMMAND_PUT 、 COMMAND_USE 。
它分别定义了一系列 beanstalkd 的命令。
之所以把 put 、 use 等命令,以常量的形式存储,是为了将「具体命令」和「具体业务逻辑」剥离,并将「具体命令」放在最高级抽象的接口中。
这样,如果 beanstalkd 更新后更改了某些命令,如,将 put 改成 put1 ,我们的 pheanstalk 只需要更新 CommandInterface 即可,而其它「相对具体」的代码中,使用的是 CommandInterface 的常量,不会受到影响。
这是利用接口解耦的思路。
而这里的常量,一般用于组装要发送到 beanstalkd server 的命令行字符串。
方法
| 方法 | 描述 |
|---|---|
| getCommandLine | 获取当前命令行的字符串形式,会返回即将发送给 beanstalkd server 的命令行字符串形式,但不包括 CRLF ,即 \r\n |
| hasData | 此命令是否存在 data |
| getData | 返回此命令的 data 数据 |
| getDataLength | 返回此命令 data 的 bytes |
| getResponseParser | 返回 ResponseParser 实例 |
ResponseInterface
这个接口,定义了一个 beanstalkd 返回实例该有的常量和方法。
常量
此接口下的所有常量,都以 RESPONSE_ 作为前缀,分别定义了 beanstalkd 可能返回的响应前缀,即响应中大写的那一部分。(可以回头参考下 beanstalkd 的协议)
这里的常量,也是用于组装 beantalkd 返回的命令行字符串。
方法
| 方法 | 描述 |
|---|---|
| getResponseName | 获取 response 的名字,一般指此 response 是哪个命令的 |
ResponseParserInterface
方法
| 方法 | 描述 |
|---|---|
| parseResponse | 将 beanstalkd 返回的命令行字符串,解析为 Response Object |
SocketFactoryInterface
方法
| 方法 | 描述 |
|---|---|
| create | 返回一个 socket 连接 |
SocketInterface
此接口定义了 Socket 类所必须存在的操作,Socket 类主要处理和 beastalkd 通信相关事项。
方法
| 方法 | 描述 |
|---|---|
| write | 向 socket 写入数据 |
| read | 从 socket 读取指定字节量的数据 |
| getLine | 获取下一行 |
| disconnect | 关闭 socket 连接 |
十二、Pheanstalk 使用手册
在过了一遍 contracts 之后,我们可以发现,pheanstalk 最接近用户层(开发者)的接口,就是 PheanstalkInterface 。
那么,使用手册,我们也通过解读 PheanstalkInterface 的具体实现 Pheanstalk 类来撰写。
建立连接
1 | include_once "vendor/autoload.php"; |
上面的 create 方法,第一个参数必填,需要传入目标 beanstalkd 服务器的 ip ,前提是,对于 beanstalkd server 而言,你的 ip (可能是内网,也可能是外网,也可能是本机),必须在它的监听列表中。
第二个参数是端口,可不填,默认为 11300 ,当然你可以修改。
第三个参数是连接超时时间,可不填,默认为 10 ,表示 10 秒之后还未连接成功就超时了。
要注意的是:此 create 方法只是返回一个配置好的 pheanstalk 实例,但并非是一个连接好的实例。
如何理解呢?
从实现上, pheanstalk 的流程是等到有指令了,也就是有 dispatch 指令后,才建立一个 socket 连接,而它与 beanstalkd 通信的底层,用的也是 socket 。
所以,如果你只写了 create 方法,并不能看出是否能够连接成功。
你还需要发送一个指令才能知道是否能够连接成功。
一旦发送过指令之后,Pheanstalk->connection->socket 就会指向一个 socket 资源。
关闭、重连
虽然,我们能看到 Pheanstalkd 类中,有 reconnect 方法,还有 $this->connection 的属性。
然而它们的访问权限是 private 。
这告诉我们,关闭和重连,不需要我们手动操作。
我们可以看到,这两个方法,只有在 pheanstalk 向 beanstalkd 发送指令时,会用到。
因为 PHP 使用 socket 连接时,socket 是有生命周期的,超出一定时间 socket 就会失效,此时,Pheanstalk 的 dispatch 方法就会自动重连。
我们知道,pheanstalk 的底层通信基于 php 的 socket ,那么,必然具备 socket 的特性,再深入的内容,可以参考 php 手册中的 socket 部分。
生产者操作
选择 tube
1 | $conn->useTube('myTube'); // 会返回 this ,因此支持链式操作 |
put job
1 | $job = $conn->put('this is my first job !'); |
这里传入的字符串,就是放到 beanstalkd 中 job 的 body
当然,关于 priority 、 delay 、 ttr 这些参数你可以在 body 后面传入,具体可参考方法接口。
put 会返回一个 Job 实例,如下:
1 | Pheanstalk\Job Object |
链式操作
1 | $job = $conn->useTube('myTube')->put('this is my 2nd job !'); |
默认 Tube
我们知道,默认的 Tube 是 default ,如果我们不使用 useTube 的话,put 的 job 就会在 default tube 中。
消费者操作
接收 job
reserve
1 | $job = $conn->reserve(); // 默认情况会接收 default tube 的 job |
上面返回的一定是 Job 实例。
reserveWithTimeOut
1 | try { |
注意:这个方法,超时的话会返回 null ,成功的话,会返回一个 Job 实例。
还有,上面代码片段中有一行 sleep ,这一行的作用,是做一个小实验。
当,job 被成功返回过来,但没有 sleep 这一行,你会发现,你连续运行两次该代码,返回的 job 是同一个。
理论上,我们应该接收到下一个 job ,因为这个 job 被接收了之后,状态就变成 reserved 而不再是 ready 。
那如何来测试 job 是否真的变成 reserved 了呢?
这就是 sleep 的用处,步骤如下:
- 先往你的 beanstalkd 加入两个 job
- 再在两个 cli 窗口运行两次含 sleep 的消费者代码
你会发现这个情况,如下图: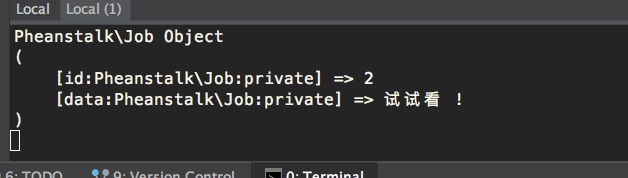
它们分别接收了两个 job 。
这里不要用 web 测试,用 cli 才能更直观地看到效果。
这个现象,也很好理解:
- reserve 成功之后,你的 php 进程还在于 beanstalkd 保持着 socket 连接,此连接不销毁,beanstalkd 都会为你冻结此 job 。
- 一旦 php 进程销毁(执行结束),beanstalkd 没有接收到其他对 job 的操作,自然就回到 ready 队列中了
删除 job
1 | $conn->delete($job2); |
这个方法没有返回值,但如果出错的话,会抛出异常。
一般在 job 被消费者处理完毕之后才调用 delete 方法。
释放 reserved job
1 | $conn->release($job,$priority,$delay); |
此方法没有返回值,如果出错会抛出异常。
此方法可以将 reserved job 重新放回 ready 队列中,一般在消费者逻辑处理失败后,才使用这个方法。
预留
1 | $conn->bury($job,$priority); |
此方法没有返回值,如果出错会抛出异常。
此方法可以将一个 job 操作为 buried 状态,比如当你的消费者接收到这个 job 时,对 job 进行了一系列检查,经检查,发现这个 job 还不能被消费,此时可以将 job 操作为 buried ,直到有客户端对这个 job 发送了 kick 指令,才会被再次 reserve 。
延迟 ttr
1 | $conn->touch($job); |
此方法没有返回值,如果出错会抛出异常。
添加监听的管道
1 | $conn->watch('test')->watch('sms'); |
此方法返回 $conn 本身,可链式操作,每次运行,都会为 watch list 添加一个 tube 。
删除监听的管道
1 | $conn->ignore('email')->ignore('sms'); |
此方法返回 $conn 本身,可链式操作,每次运行,都会从 watch list 中移除一个 tube 。
默认,watch list 中会有一个 default ,所以,当你执行 watch 时,default 仍然在 watch list 中。
仅监听一个管道
1 | $conn->watchOnly('sms'); |
此方法返回 $conn 本身,可链式操作。
通过此快捷方法,可以一次性移除 watch list 中所有的 tube ,除了此方法传入的 tube 以外。
其他命令
单纯获取 job
1 | $conn->peek(new \Pheanstalk\Job(1,'')); // 根据 id 获取 job ,id 在 beanstalkd 是唯一的,不论处于什么 tube |
这里的 peekReady 、 peekDelayed 、 peekBuried 虽然在译文解释中,提到「下一个」,但它并非是一个指针,当你调用一起 peekReady ,下一次再调用 peekReady 就自动将指针移动到「下一个」。如果你不手动将当前得到的 Job 操作为其他状态,或者延长延迟时间等,你多次调用 peek 命令,他将返回同一个 Job。
批量操作 job 为 ready
1 | $conn->useTube('order'); |
上面的代码片段,是针对 order tube 操作 10 条 buried 或 delayed 为 ready 。
具体可以看 beanstalkd 译文中的 kick 命令。
操作指定 job 为 ready
1 | $conn->useTube('sms')->kickJob($job); |
此方法没有返回值。
获取 job 的统计信息
1 | $job = $conn->reserve(); |
此方法返回一个 ArrayResponse 实例,具体字段意义,需参考 beanstalkd 译文。
$res 如下:
1 | Pheanstalk\Response\ArrayResponse Object |
获取 tube 统计信息
1 | $res = $conn->statsTube('default'); |
此方法返回一个 ArrayResponse 实例,具体字段意义,需参考 beanstalkd 译文。
$res 如下:
1 | Pheanstalk\Response\ArrayResponse Object |
获取 beanstalkd 服务器统计信息
1 | $res = $conn->stats(); |
此方法返回一个 ArrayResponse 实例,具体字段意义,需参考 beanstalkd 译文。
$res 如下:
1 | Pheanstalk\Response\ArrayResponse Object |
查看当前 tube 列表
1 | $res = $conn->listTubes(); |
此方法将返回一个数组,如下:
1 | Array |
查看当前 use 的 tube 列表
1 | $res = $conn->listTubeUsed(); |
此方法返回一个字符串,为当前 used 的 tube 名。
注意,同一时间,只有一个 tube 会被 used 。
查看当前 watch list
1 | $res = $conn->listTubesWatched(); |
此方法将返回一个数组,如下:
1 | Array |
冻结 tube
1 | $conn->pauseTube('default',90); |
此方法没有返回值,会将 tube 冻结 90 秒,冻结期间,消费者无法 reserve job ,如果 tube 冻结后,有客户端发送了 reserve 指令,则会阻塞,直到冻结结束,或 reserve time out 。
- Post title:Beanstalkd 笔记
- Post author:Yuxuan Wu
- Create time:2021-03-25 20:07:32
- Post link:yuxuanwu17.github.io2021/03/25/2021-03-26-Beanstalkd-笔记/
- Copyright Notice:All articles in this blog are licensed under BY-NC-SA unless stating additionally.