完成学校Matlab作业后的一些总结,数据可以从我的GitHub账户下载。作为一名Matlab的初学者,请多多海涵
数据在此
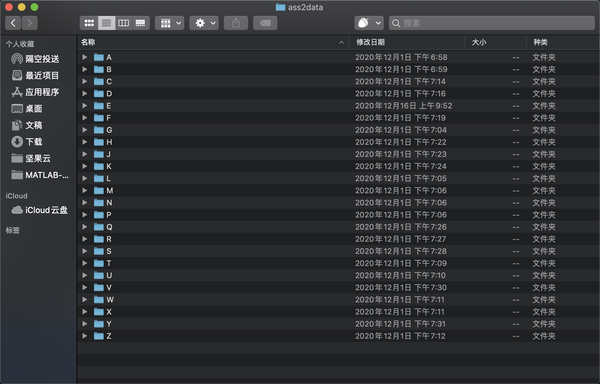
数据是来自车牌号图片(冷知识:I,O天生是在车牌里不出现的)。一共24个文件夹,每个文件夹里有100张图片,所以一共有2400张图片。这次的项目是构建预测模型来进行图像识别。
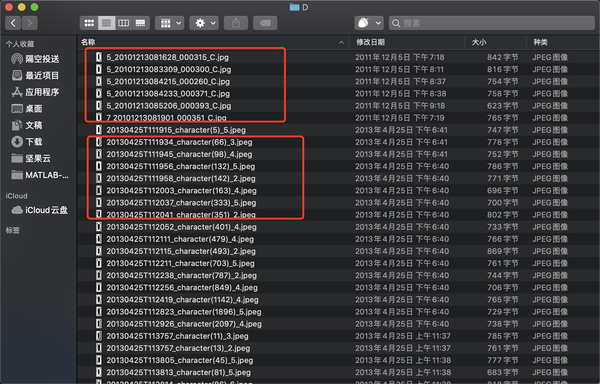
我们打开这些文件,查看图片的详细信息
我们发现这里面的图片格式不一致,且命名没有统一规律。
下文开始处理图片数据,并将每一张照片提取出来,用Matlab分析
方法一:暴力修改文档法 核心思路:将图片全部提取出来,然后统一格式,统一名称,保存在一个新的文件夹里
参考 matlab遍历文件夹下所有图片和遍历所有子文件夹下图片_无鞋童鞋的博客-CSDN博客_matlab遍历文件夹下子文件夹所有文件
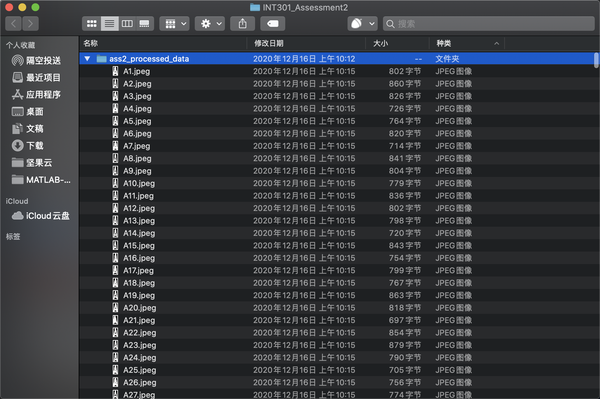
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 imgDataPath = '../INT301_Assessment2/ass2data/' ; imgDataDir = dir(imgDataPath); savepath = '../INT301_Assessment2/ass2_processed_data/' ; for i = 1 :length (imgDataDir) if (isequal (imgDataDir(i ).name,'.' )||... isequal (imgDataDir(i ).name,'..' )||... isequal (imgDataDir(i ).name,'.DS_Store' )||... ~imgDataDir(i ).isdir) continue ; end imgDir_jpeg = dir([imgDataPath imgDataDir(i ).name '/*.jpeg' ]); imgDir_jpg = dir([imgDataPath imgDataDir(i ).name '/*.jpg' ]); imgDir = [imgDir_jpeg',imgDir_jpg']'; for j =1 :length (imgDir) img = imread([imgDataPath imgDataDir(i ).name '/' imgDir(j ).name]); imwrite(img, [savepath,imgDataDir(i ).name,num2str(j ),'.jpeg' ]) end end
新建立的文件夹,检查一下有没有漏,可以直接看每个字母的最后一个是不是”字母100.jpeg”
处理单个图片,以矩阵形式保存倒入的图片 下图getimdata2这个函数输入的是重写后的新文件夹地址,输出的是训练集X和标签y (这里用数字代指标签)
不好意思有点懒得动脑子了,就直接写了24个if,大家可以随意优化
如果继续处理例如转换为onehot之类的可以直接用ind2vec来转换
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 function [ data,target ] = getimdata2 (path) files = dir([path '*.jpeg' ]); data=[]; target=[]; for file = files' im = imread([path file.name]); im = double(im); im = im/255 ; data = [data im(:)]; if strcmp(file.name(1 ),'A' ) target=[target [1 ]]; elseif strcmp(file.name(1 ),'B' ) target=[target [2 ]]; elseif strcmp(file.name(1 ),'C' ) target=[target [3 ]]; elseif strcmp(file.name(1 ),'D' ) target=[target [4 ]]; elseif strcmp(file.name(1 ),'E' ) target=[target [5 ]]; elseif strcmp(file.name(1 ),'F' ) target=[target [6 ]]; elseif strcmp(file.name(1 ),'G' ) target=[target [7 ]]; elseif strcmp(file.name(1 ),'H' ) target=[target [8 ]]; elseif strcmp(file.name(1 ),'J' ) target=[target [9 ]]; elseif strcmp(file.name(1 ),'K' ) target=[target [10 ]]; elseif strcmp(file.name(1 ),'L' ) target=[target [11 ]]; elseif strcmp(file.name(1 ),'M' ) target=[target [12 ]]; elseif strcmp(file.name(1 ),'N' ) target=[target [13 ]]; elseif strcmp(file.name(1 ),'P' ) target=[target [14 ]]; elseif strcmp(file.name(1 ),'Q' ) target=[target [15 ]]; elseif strcmp(file.name(1 ),'R' ) target=[target [16 ]]; elseif strcmp(file.name(1 ),'S' ) target=[target [17 ]]; elseif strcmp(file.name(1 ),'T' ) target=[target [18 ]]; elseif strcmp(file.name(1 ),'U' ) target=[target [19 ]]; elseif strcmp(file.name(1 ),'V' ) target=[target [20 ]]; elseif strcmp(file.name(1 ),'W' ) target=[target [21 ]]; elseif strcmp(file.name(1 ),'X' ) target=[target [22 ]]; elseif strcmp(file.name(1 ),'Y' ) target=[target [23 ]]; elseif strcmp(file.name(1 ),'Z' ) target=[target [24 ]]; end end end
另外一个getimdata 函数和上面大体差不多,但是输出的是已经onehot encoding后的结果(e.g. A-> (1,0,0,…0))标签用一个1*24的向量来表示
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 function [ data,target ] = getimdata (path) files = dir([path '*.jpeg' ]); data=[]; target=[]; store = cell(1 ,24 ); tst_zero = zeros (1 ,24 ); for i = 1 :24 copy = tst_zero; copy(1 ,i ) = 1 ; store{i } = copy; end for file = files' im = imread([path file.name]); im = double(im); im = im/255 ; data = [data im(:)]; test_zero = zeros (1 ,24 ); if strcmp(file.name(1 ),'A' ) target=[target [store{1 }]']; elseif strcmp(file.name(1 ),'B' ) target=[target [store{2 }]']; elseif strcmp(file.name(1 ),'C' ) target=[target [store{3 }]']; elseif strcmp(file.name(1 ),'D' ) target=[target [store{4 }]']; elseif strcmp(file.name(1 ),'E' ) target=[target [store{5 }]']; elseif strcmp(file.name(1 ),'F' ) target=[target [store{6 }]']; elseif strcmp(file.name(1 ),'G' ) target=[target [store{7 }]']; elseif strcmp(file.name(1 ),'H' ) target=[target [store{8 }]']; elseif strcmp(file.name(1 ),'J' ) target=[target [store{9 }]']; elseif strcmp(file.name(1 ),'K' ) target=[target [store{10 }]']; elseif strcmp(file.name(1 ),'L' ) target=[target [store{11 }]']; elseif strcmp(file.name(1 ),'M' ) target=[target [store{12 }]']; elseif strcmp(file.name(1 ),'N' ) target=[target [store{13 }]']; elseif strcmp(file.name(1 ),'P' ) target=[target [store{14 }]']; elseif strcmp(file.name(1 ),'Q' ) target=[target [store{15 }]']; elseif strcmp(file.name(1 ),'R' ) target=[target [store{16 }]']; elseif strcmp(file.name(1 ),'S' ) target=[target [store{17 }]']; elseif strcmp(file.name(1 ),'T' ) target=[target [store{18 }]']; elseif strcmp(file.name(1 ),'U' ) target=[target [store{19 }]']; elseif strcmp(file.name(1 ),'V' ) target=[target [store{20 }]']; elseif strcmp(file.name(1 ),'W' ) target=[target [store{21 }]']; elseif strcmp(file.name(1 ),'X' ) target=[target [store{22 }]']; elseif strcmp(file.name(1 ),'Y' ) target=[target [store{23 }]']; elseif strcmp(file.name(1 ),'Z' ) target=[target [store{24 }]']; end end end
方法二:利用imageDatastore 简便的方法永远是在你写完做完后发现的🙄
imageDatastore 可以直接读取你这个文件夹下的所有子文件及其图片
下面的代码是直接将数据集和标签都已经分好处理好了,可以直接喂到模型里面去的
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 clc; clear; F = '../INT301_Assessment2/ass2data' ; imds = imageDatastore(F,'IncludeSubfolders' ,true ,'LabelSource' ,'foldernames' ); labelCount = countEachLabel(imds); numTrainFiles = 80 ; [imdsTrain, imdsTest] = splitEachLabel(imds, numTrainFiles,'randomize' ); data = []; files = imdsTrain.Files; x = 0 ; for file = files' im = imread(file{1 }); im = double(im); im = im/255 ; data = [data im(:)]; end X_train = data'; y_train = imdsTrain.Labels; y_train = label_preprocess(y_train); data = [] files = imdsTest.Files; x = 0 for file = files' im = imread(file{1 }); im = double(im); im = im/255 ; data = [data im(:)]; end X_test = data'; y_test = imdsTest.Labels; y_test = label_preprocess(y_test);
这里我将那24个 if 打包写成了一个新的函数叫label_preprocess,输入的是标签,输出的是onehot encoding后的结果
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 function [target] = label_preprocess (y_train) target = []; for y = y_train' if y == 'A' target=[target [1 ]]; elseif y=='B' target=[target [2 ]]; elseif y=='C' target=[target [3 ]]; elseif y=='D' target=[target [4 ]]; elseif y=='E' target=[target [5 ]]; elseif y=='F' target=[target [6 ]]; elseif y=='G' target=[target [7 ]]; elseif y=='H' target=[target [8 ]]; elseif y=='J' target=[target [9 ]]; elseif y=='K' target=[target [10 ]]; elseif y=='L' target=[target [11 ]]; elseif y=='M' target=[target [12 ]]; elseif y=='N' target=[target [13 ]]; elseif y=='P' target=[target [14 ]]; elseif y=='Q' target=[target [15 ]]; elseif y=='R' target=[target [16 ]]; elseif y=='S' target=[target [17 ]]; elseif y=='T' target=[target [18 ]]; elseif y=='U' target=[target [19 ]]; elseif y=='V' target=[target [20 ]]; elseif y=='W' target=[target [21 ]]; elseif y=='X' target=[target [22 ]]; elseif y=='Y' target=[target [23 ]]; elseif y=='Z' target=[target [24 ]]; end end target =ind2vec(target); target = target';
方法三:直接读取.g格式(仅限本题使用) 因为jpeg和jpg都是以g结尾,所以可以本题可以直读取g。代码就略了