书接上文
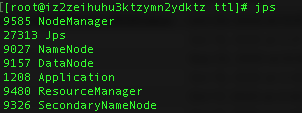
首先检查java 环境和Hadoop 环境是否配置妥当, 并且检查Hadoop是否已经启动
1 | hadoop version |

1 | java -version |

1 | jps |
本文章用到的WordCount使用自web,java文件如有需要请在下方连接下载(如有机会,大家给我GitHub账户点个关注,谢谢)(如果是xjtlu的小伙伴,暂时不要用老师给的wordcount.java,因为反正不知道什么原因我这个方法就是运行不出来,如果只是需要check一下他配置的好不好,可以直接拿我这个确定的可以成功的script来试一下)
https://github.com/yuxuanwu17/Hadoop/blob/main/WordCount_success.java
这里推荐一个传文件的图形化界面,可以直接拖拽,这样就不用繁琐的scp语句
Windows: wincsp
https://winscp.net/eng/download.php
MAC: FileZilla
Download FileZilla Client for Mac OS X
对上述两app的具体操作可以看官方文档,这里不再赘述
以下以MAC:FileZilla 为例子

再这儿输入你的主机用户名和密码,这里通常以root权限来操作,然后端口22(ssh连接)
连接成功后,进入如下的界面
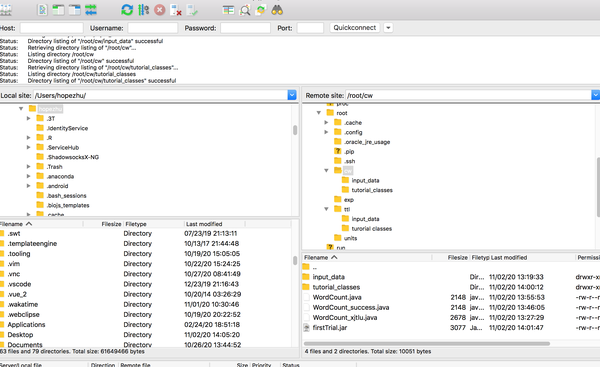
然后你可以在你的远端服务器上右键,“Create Directory”,我这里面叫cw里面包含两个子文件 “inputdata”和“tutorial_classes”,并且把之前提到的java文件“WordCount”拖入到cw这个子文件下,效果图如下。

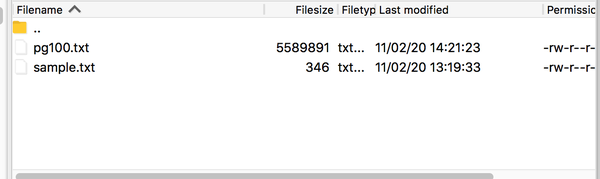
这儿的input_data 需要存放你等会需要处理的文件,pg100是我们test的对象
接下来配置Hadoop的路径之类的,同理,terminal打开,进入你的阿里云服务器
配置HADOOP_CLASSPATH (注意,如果是关闭后打开,记得重新运行一下这行代码,原因暂时不知道,若有知道的请评论区告诉呀)
1 | export HADOOP_CLASSPATH=$(hadoop classpath) |
同时输出以下HADOOP_CLASSPATH 来看一下是否成功
1 | echo $HADOOP_CLASSPATH |
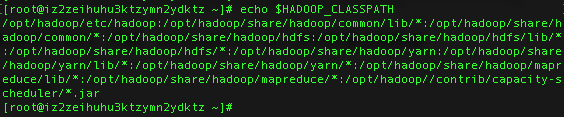
若出现如下结果则说明一切运行成功
接下来在HDFS上创建一个文件
1 | hadoop fs -mkdir /pg100 |
打开你的50070 端口,在右上角的Utilities里面的Browse the file system可以查看

再在这个文件里创建一个子文件
1 | hadoop fs -mkdir /pg100/input |
然后你点入那个pg100,就会发现有个input,此时里面暂时还没有文件

下来你需要upload你的文件到input地址下
1 | hadoop fs -put '/root/cw/input_data/pg100.txt' /pg100/input |
然后你就会发现如下情况,说明已经上传成功了
下来需要在terminal进入你的cw文件, 来运行你的java code 以下操作都cw路径底下操作
1 | cd cw |
进入成功后
1 | javac -classpath ${HADOOP_CLASSPATH} -d '/root/cw/tutorial_classes' '/root/cw/WordCount.java' |
上述的意思是将java 文件里的class compile到tutorial_classes
结果是在路径底下会出现三个class文件
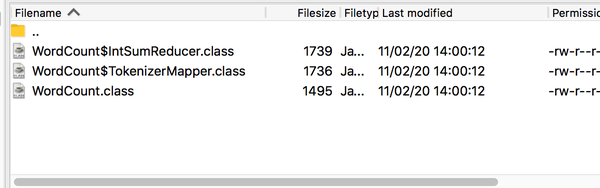
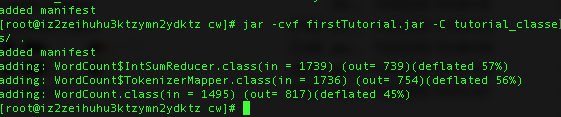
下来需要将output出来的三个文件放在一个jar文件里
1 | jar -cvf firstTrial.jar -C tutorial_classes/ . |
下来是在Hadoop上运行jar文件
1 | hadoop jar '/root/cw/firstTrial.jar' WordCount /pg100/input /pg100/output |
注意:中间的WordCount指的是之前那个java文件的Class后面,注意下面只是上文的格式,不用运行!!
1 | hadoop jar <jar_file> <class_name> <HDFS_input_directory> <HDFS_output_directory> |
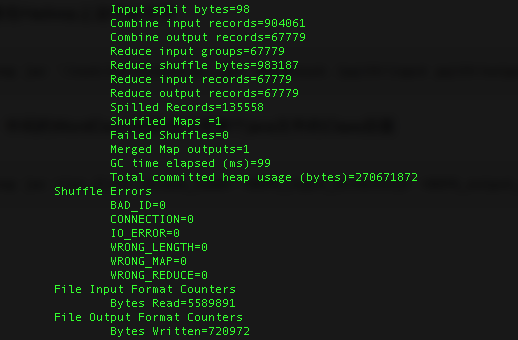
结果
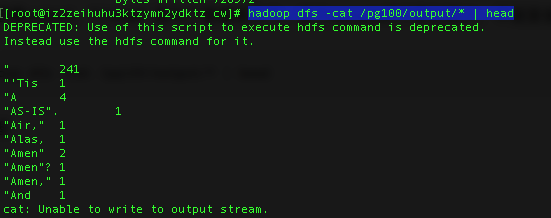
可以查看output,“| head” 是为了查看前几个,这个sample的个数比较大,不适宜全部展开
1 | hadoop dfs -cat /pg100/output/* | head |
效果图
如有问题,欢迎在评论区指出呀,写文件不容易,求点赞
- Post title:阿里云Hadoop第二弹(运行WordCount)
- Post author:Yuxuan Wu
- Create time:2021-01-25 20:36:27
- Post link:yuxuanwu17.github.io2021/01/25/阿里云Hadoop第二弹(运行WordCount)/
- Copyright Notice:All articles in this blog are licensed under BY-NC-SA unless stating additionally.